Get a Free WorkTrek Demo
Let's show you how WorkTrek can help you optimize your maintenance operation.
Try for freeMTTR stands for Mean Time to Repair. It’s a key metric that measures how quickly systems can be fixed after breaking down. MTTR helps companies understand and improve their reliability and availability. When equipment fails, it costs time and money. A low MTTR shows that repairs happen fast, which means less downtime and happier customers.

Source: WorkTrek
Companies track MTTR to spot problems and improve their repair processes. MTTR helps identify areas for improvement in repair procedures. It can reveal if teams need more training or better tools. Tracking MTTR over time shows if maintenance strategies are working.
MTTR applies to many systems, such as factory machines, computer networks, and software. By focusing on MTTR, businesses can boost their efficiency and stay competitive.
Calculating MTTR

The MTTR formula is:
MTTR = Total Repair Time / Number of Repairs
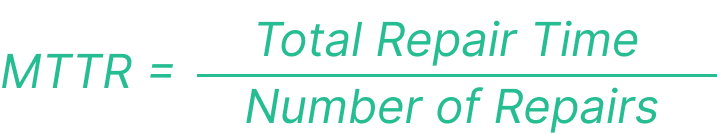 Source: WorkTrek
Source: WorkTrek
This calculation gives the average time it takes to fix an issue. To use this formula, add up all the repair times for a set period. Then divide by the number of repairs done in that time.
For example, if a company had five repairs that took 2, 3, 1, 4, and 5 hours:
Total Repair Time = 15 hours Number of Repairs = 5 MTTR = 15 / 5 = 3 hours
Listen to a Podcast on MTTR
Components of MTTR
MTTR includes several stages in the repair process:
- Detection: Identifying that a failure has occurred
- Diagnosis: Finding the cause of the problem
- Repair: Fixing the issue
- Testing: Ensuring the system works correctly
The clock starts when a failure is detected and stops when the system is back online. MTTR doesn’t include time spent waiting for parts or technicians.

Illustration: WorkTrek/ Quote: Splunk
Factors that can affect MTTR:
- Skill level of maintenance staff
- Availability of spare parts
- Quality of diagnostic tools
- Complexity of the system
Reducing any of these factors can help lower MTTR and improve system reliability.
MTTR vs. Other Metrics
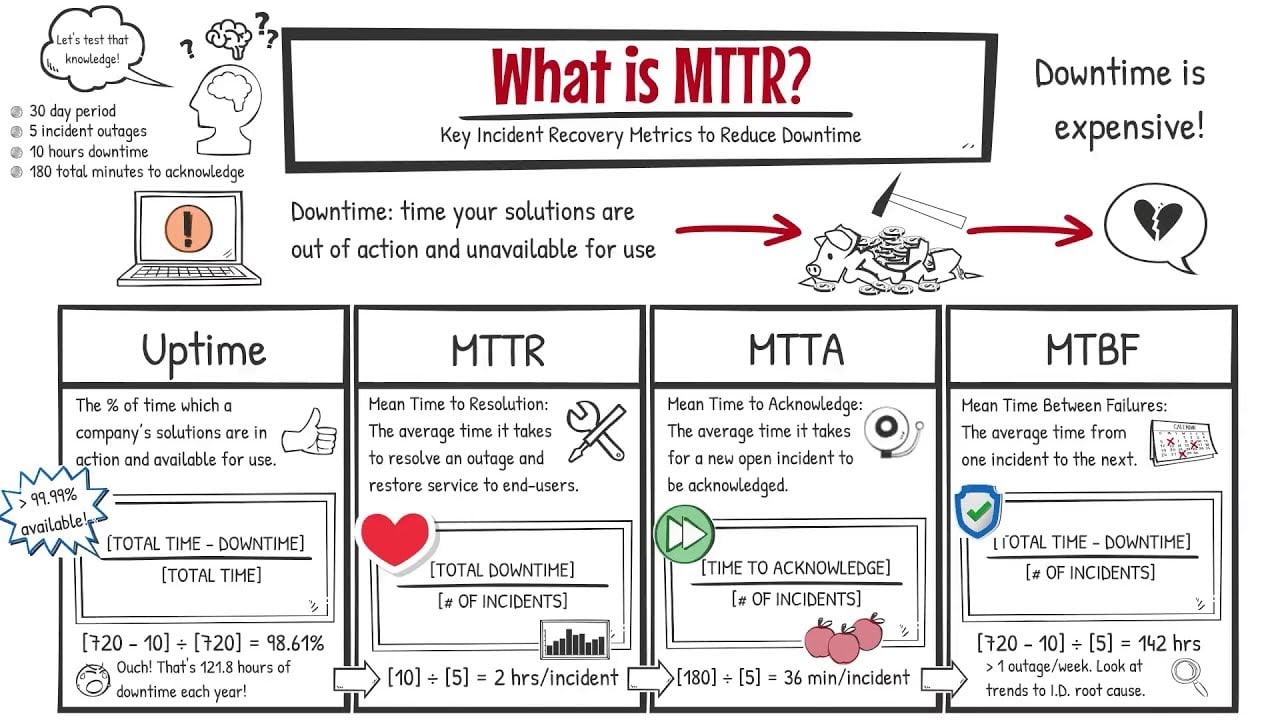
MTTR is one of several metrics used to measure system performance. It works alongside other important measures:
- MTBF (Mean Time Between Failures): The average time between system failures
- MTTF (Mean Time to Failure): The average time until a system fails
- Availability: The percentage of time a system is operational
MTTR + MTBF = MTTO (Mean Time to Operations)
This formula shows how MTTR and MTBF work together to measure total downtime. A low MTTR combined with a high MTBF indicates a reliable system with quick repairs.
While MTTR focuses on repair time, MTBF and MTTF look at the frequency of failures. These metrics give a complete picture of system reliability and maintenance effectiveness.
Collecting Performance Data
Good data collection is key for accurate MTTR. Companies need to track:
- Start and end times of each repair
- Type of equipment or system repaired
- Cause of the breakdown
- Steps taken to fix the issue
Illustration: WorkTrek/ Quote: Forbes
Using software like a CMMS system to log this info can make data collection more accessible and precise. Training staff on proper data entry is important to ensure correct calculations.

Regular reviews of repair logs can help spot trends and areas for improvement.
Benchmarking Against Industry Standards
Comparing MTTR to industry standards helps businesses gauge their performance. Steps for benchmarking include:
- Find reliable sources for industry data
- Compare MTTR to similar companies
- Look at top performers in the field
- Set goals based on these comparisons

Illustration: WorkTrek/ Quote: ReliablePlant
Company size, equipment type, and operating conditions can affect MTTR. When benchmarking, aim to match these factors.
Regular benchmarking can drive continuous improvement in maintenance processes.
Maintenance Strategies to Improve MTTR
Companies can use several key strategies to reduce their Mean Time to Repair (MTTR). These approaches focus on preventing issues, using data to predict problems, and improving maintenance team skills.
Preventive Maintenance
Preventive maintenance helps catch problems early. Fixing small issues before they become big ones can lower MTTR.
 Illustration: WorkTrek / Data: Gecko
Illustration: WorkTrek / Data: Gecko
Regular checks and part replacements are key. For example, a factory might change machine oil every month. This stops breakdowns from happening in the first place.
Keeping good records is also important. Teams can track when parts were last replaced, which helps them better plan future maintenance.
Predictive Maintenance and Analytics
Predictive maintenance uses data to spot problems before they happen. This can significantly cut down MTTR.
Illustration: WorkTrek / Data: Bolt Data
Sensors on machines collect data constantly. Special software analyzes this data to find patterns, which can indicate when a machine might break soon.
For instance, a sensor might notice a motor running hotter than normal. The team can then fix it before it fails completely, saving time and money.
Machine learning helps make these predictions more accurate over time. As the system collects more data, it gets better at spotting issues early.
Maintenance Teams and Training
Well-trained teams can fix problems faster. This directly improves MTTR.
Regular training keeps staff up-to-date on new tech and methods. For example, teams might learn about new diagnostic tools every few months.
 Illustration: WorkTrek/ Data: Shortlister
Illustration: WorkTrek/ Data: Shortlister
Creating detailed repair guides helps too. These step-by-step instructions make repairs quicker and more consistent.
Encouraging knowledge sharing among team members is vital. Experienced staff can teach newer members tricks they’ve learned. This spreads skills across the whole team.
Tracking and Responding to Incidents
Effective incident management involves several key steps to minimize downtime and restore services quickly. These include setting up a framework, measuring response times, and finding the root causes of problems.
Incident Management Framework

Illustration: WorkTrek/ Quote: Cyberday
A solid incident management framework helps teams handle issues smoothly. This framework outlines roles, steps, and tools for dealing with problems. It typically includes:
• Incident detection and logging
• Prioritization based on impact
• Escalation to the right team members
• Communication channels for updates
The framework should be clear and easy to follow. Regular drills help teams practice their roles and improve their skills.
Mean Time to Acknowledge and Respond
Quick response is crucial for solving problems fast. Two key metrics track this:
- Mean Time to Acknowledge (MTTA): How long it takes to notice an issue
- Mean Time to Respond (MTTR): How long before work starts on fixing it
Teams aim to keep these times short. Automated alerts and on-call schedules can help. Tracking these metrics over time shows if a team is getting faster or slower at handling issues.
Root Cause Analysis
After fixing an incident, it’s important to find out why it happened. Root cause analysis digs deep into the problem. It looks for the main reason, not just surface symptoms.
Steps in root cause analysis include:
- Gather data about the incident
- Identify possible causes
- Test each cause to find the real one
- Suggest ways to prevent similar issues
This process helps stop the same problems from happening again. It also shows patterns that might point to bigger issues in systems or processes.
Improving Customer and User Experience
Reducing MTTR improves customer satisfaction and user experience. Fast problem resolution helps businesses meet service-level agreements and minimize disruption.
Aligning MTTR with User Expectations
Users expect quick issue resolution. Companies should set MTTR goals that match customer needs. Short MTTR targets work for critical systems, while longer targets may suit less vital services.

Illustration: WorkTrek/ Quote: XM Experience Management
Businesses can survey users to understand their expectations. This data helps set realistic MTTR goals. Companies should also educate users on typical resolution times. Clear communication prevents frustration.
Regular MTTR reviews ensure goals stay relevant. As technology changes, so do user needs. Keeping MTTR targets current helps maintain customer happiness.
Communication and Transparency

Illustration: WorkTrek/ Data: Deputy
Open communication during incidents builds trust. Users appreciate updates, even if issues aren’t fixed yet. Clear, timely messages show the company cares.
Status pages provide real-time information on service health. They let users check problems without contacting support, saving time for both customers and staff.
Sharing post-mortems after incidents demonstrates accountability. These reports explain what went wrong and how to prevent future issues. They show users that the company learns from mistakes.
Minimizing Business Impact
Fast MTTR reduces downtime costs. It limits lost productivity and revenue. Quick fixes also prevent damage to brand reputation.
To minimize impact, companies can:
- Use redundant systems
- Create detailed incident response plans
- Train staff on fast problem-solving
Prioritizing high-impact issues helps, too. Fixing problems that affect many users first improves overall satisfaction.
Companies should track downtime costs. This data shows the value of reducing MTTR. It can justify investments in better tools or training.