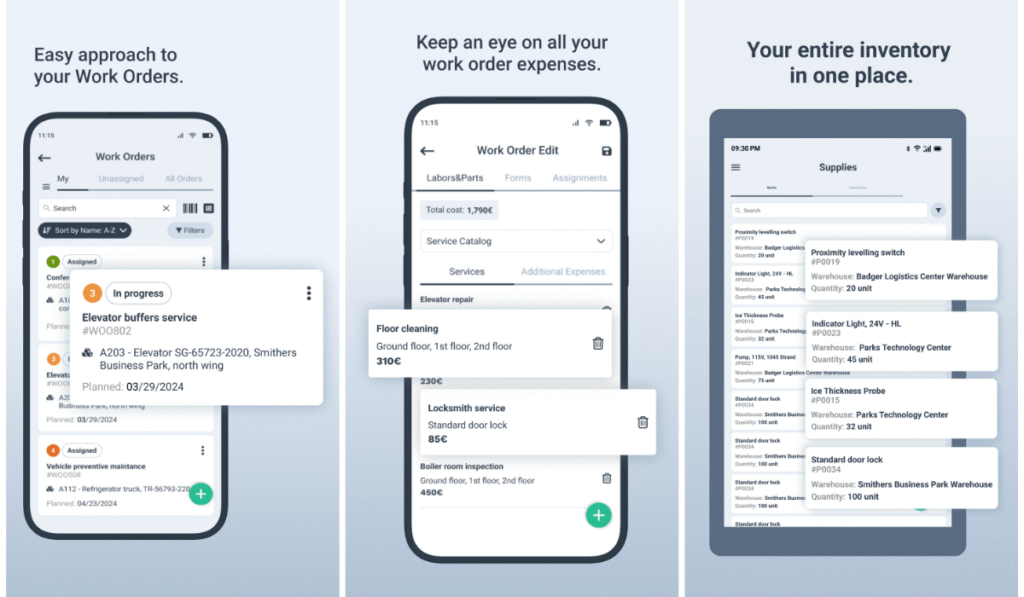
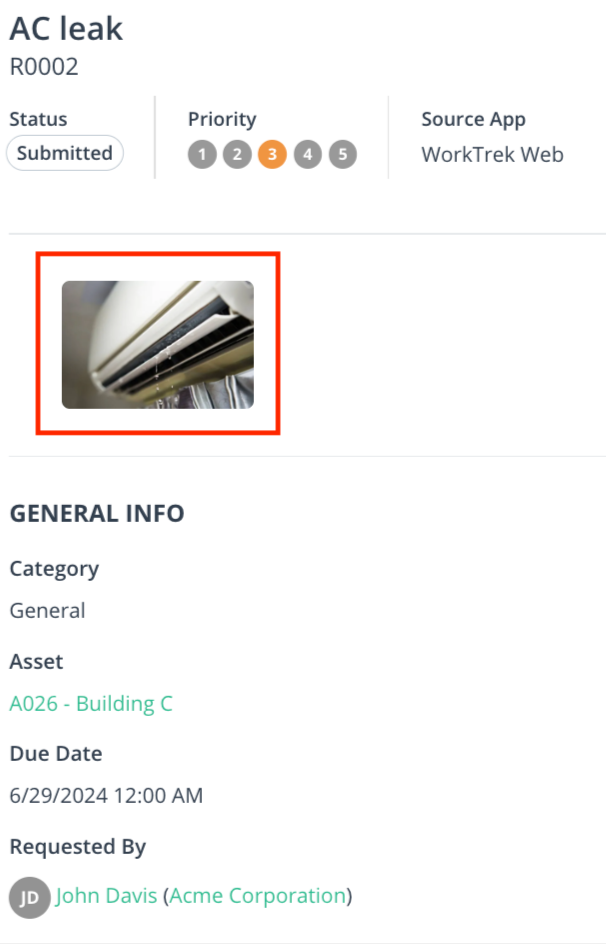
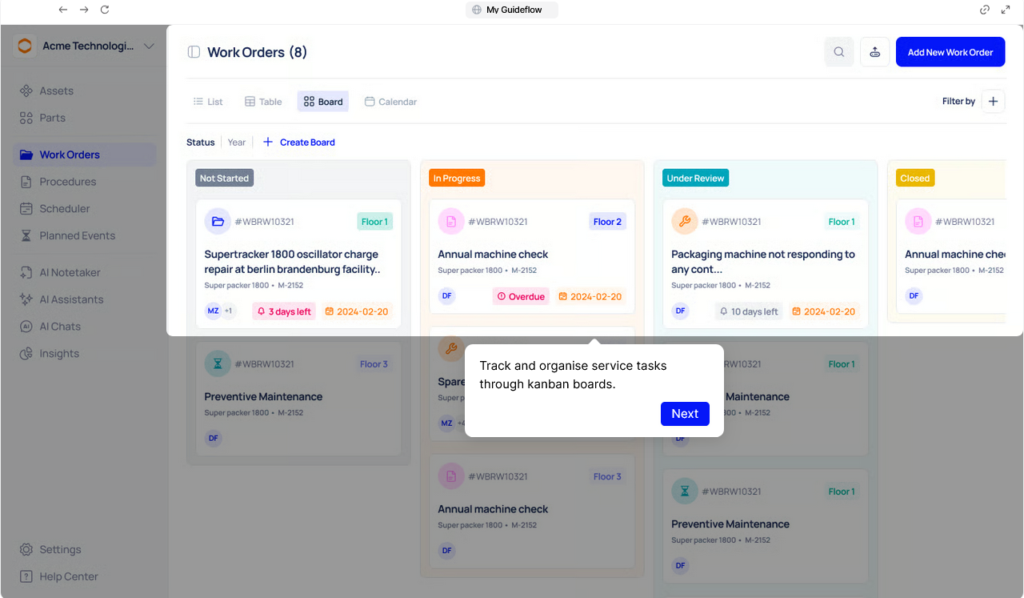
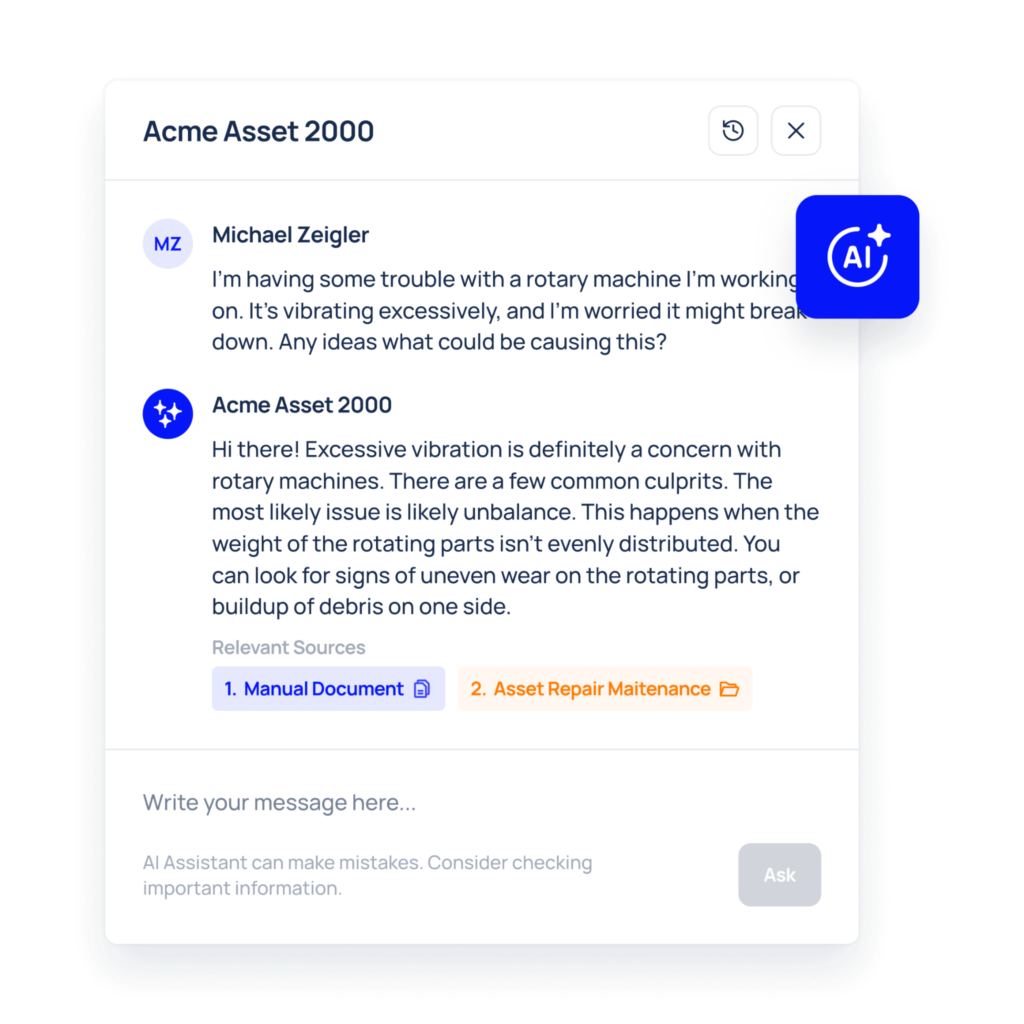
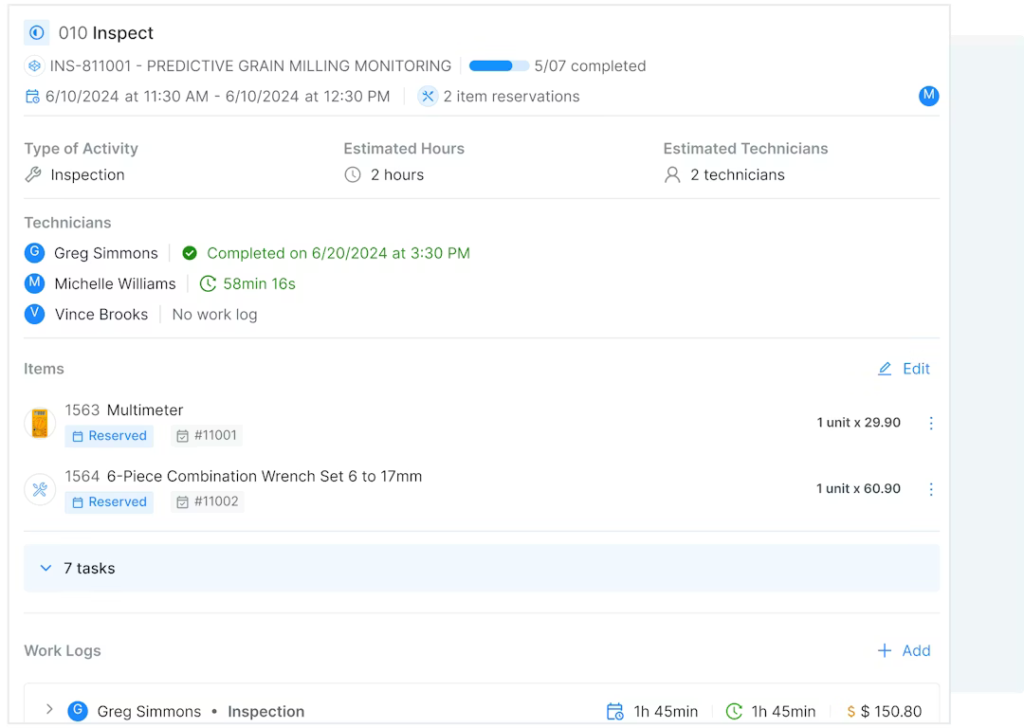
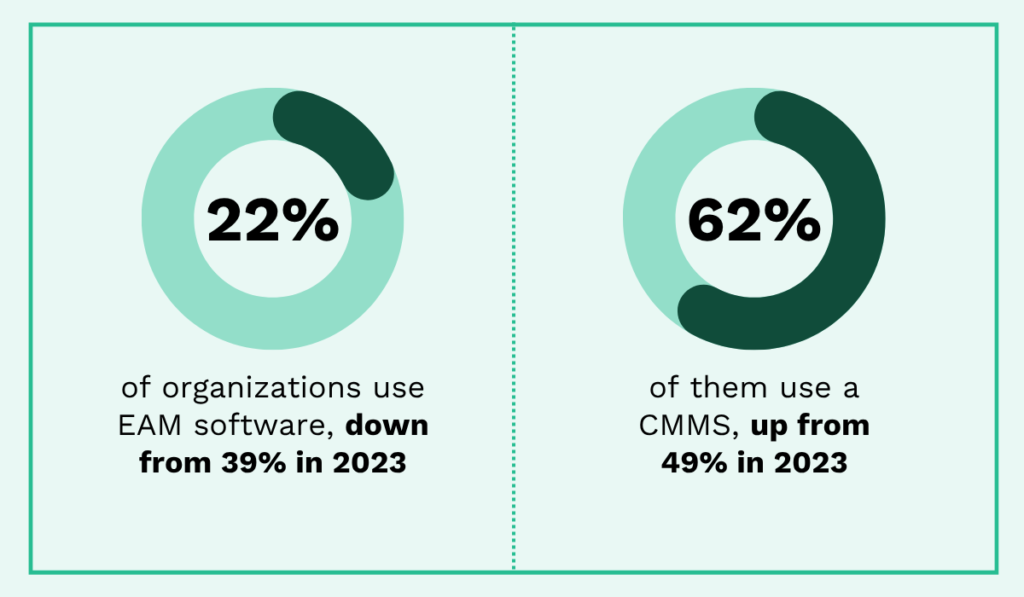
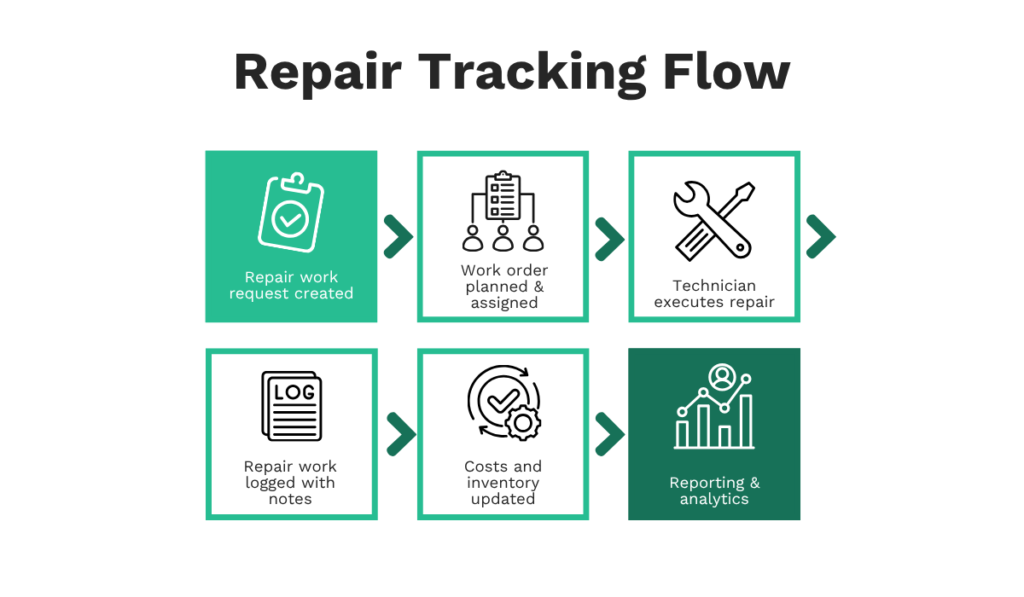
Everything You Need to Know About the Work Order Process
Key Takeaways:
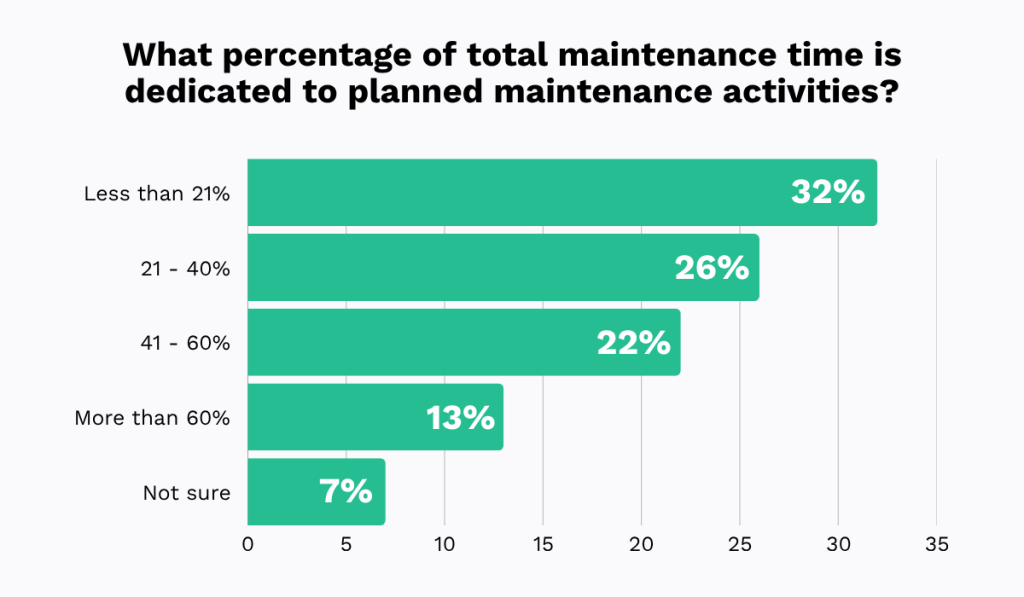
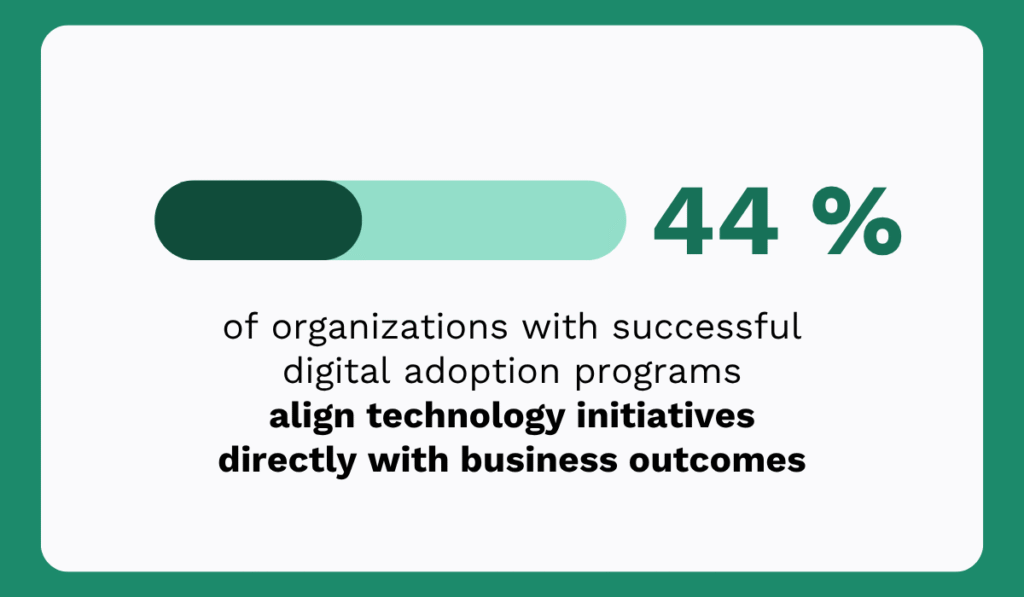
Strengthening the work order process significantly improves PM schedule compliance.
Workers spend about 25% of their workweek looking for information.
One company reduces its backlog by 70% by improving its WO process.
Many unplanned breakdowns in manufacturing facilities tell the same story: something was wrong before, but nobody caught it in time.
The warning signs were there.
A work request that never got prioritized, an inspection that kept getting deferred, or a repair that was completed but never properly documented.
The equipment didn’t fail randomly; the process around it did.
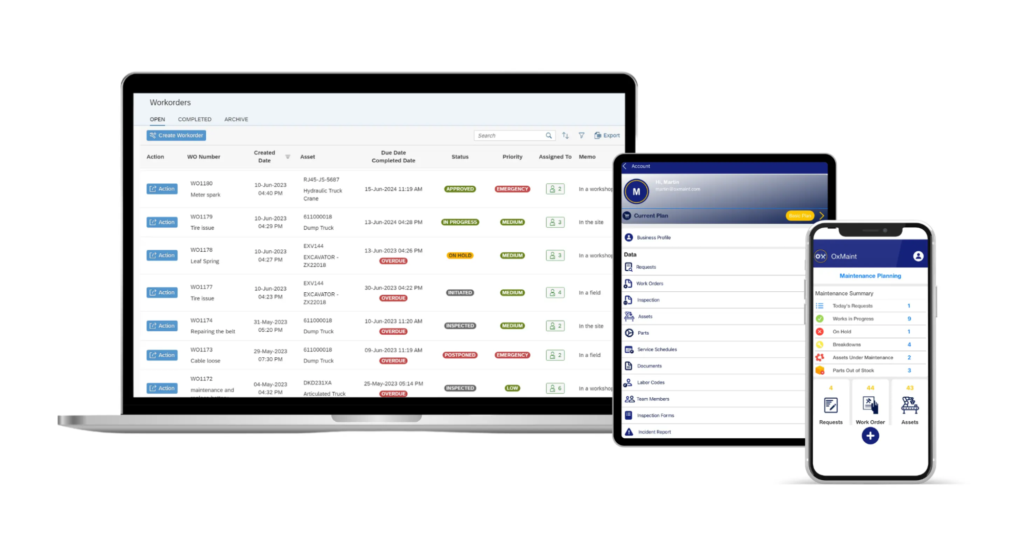
At the center of that process is the work order.
It’s where maintenance activities are requested, planned, executed, and documented.
Weaknesses in your work order process can affect nearly every aspect of maintenance, from technician productivity and preventive maintenance to equipment reliability and operational costs.
Understanding the work order process is the first step toward improving it.
In this guide, you’ll learn how a typical work order process works, the common challenges that undermine it, and how the right processes and technology can help your maintenance team operate more efficiently and proactively.
A Closer Look at a Typical Work Order Process
No two companies handle work orders in the same way.
Your process may include additional approval steps, a different ticketing system, or a unique escalation path.
While the exact workflow varies by industry, facility size, maintenance strategy, and maintenance tools, most organizations follow a similar sequence of steps when managing maintenance work:
Identify the maintenance need
A work order begins when someone identifies a maintenance issue, such as an equipment failure or a safety concern.
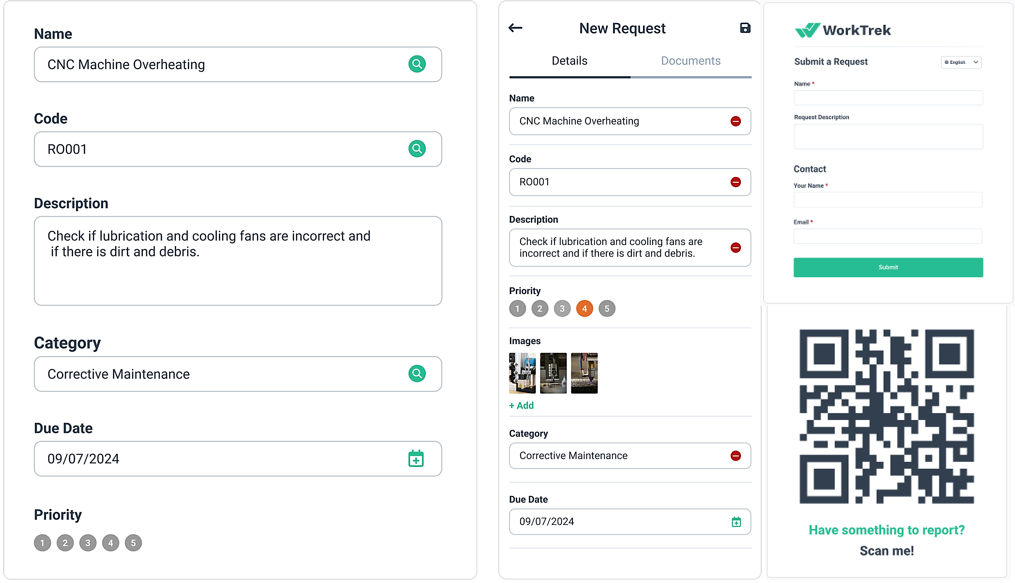
Submit a request
The request captures essential information, including the asset, issue description, priority, location, and more.
Review and approve the request
A maintenance manager verifies the request, determines its priority, and decides whether to approve it, defer it, combine it with other work, or reject it.
Plan and schedule the work
Once approved, the work order is planned and scheduled based on factors such as equipment criticality and safety.
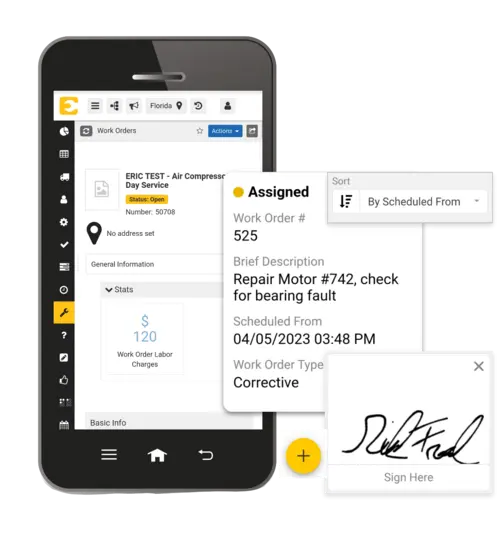
Assign the work order.
The job is assigned to the technician or team with the appropriate skills, certifications, and availability.
Complete the maintenance work
Technicians perform the task, record labor hours, document parts used, and capture any relevant observations during the repair.
Verify and close the work order
The work order is closed; the completed work is documented, creating an upkeep history that supports future planning and decision-making.
The company’s maintenance team identified gaps in its reliability program, particularly around managing corrective work orders.
Before improving its approach, the team struggled to understand where maintenance resources were being spent and lacked consistency across its facilities.
To address these challenges, Gallo created a more structured word order workflow built around five key stages: approval, planning, prioritization, scheduling, and execution.
Scheduling focuses on when a job will be completed, while planning focuses on what is required to complete it successfully, including the necessary parts, tools, procedures, and potential challenges.
By strengthening each stage of its work order process across five facilities, Gallo improved schedule compliance from 50% to 77% and gained greater control over corrective maintenance activities.
Common Work Order Problems That Sabotage the Entire Process
A work order process rarely fails because of a single mistake.
More commonly, it’s weakened by small execution gaps such as missing information, delayed approvals, or poor communication. These issues compound over time.
It’s important to understand how they affect your maintenance operation before deciding how to solve these problems.
Incomplete Work Orders
An incomplete work order might look like a minor inconvenience on paper, but it can quickly disrupt your entire maintenance process.
A technician can’t immediately begin a repair if they open a work order that’s missing an asset’s history, the required parts list, or a clear description of the problem.
Instead, they may need to track down a supervisor for more details, search through old records, or return to the equipment to diagnose the problem themselves, all before they’ve turned a single wrench.
This delays response times and shifts technicians away from productive maintenance activities toward information gathering and administrative tasks.
The impact is even greater in manufacturing environments, where conditions change constantly.
Equipment failures, production schedules, and maintenance priorities can shift throughout the day.
A delay on one work order does not occur in isolation; it can create a backlog that affects every task scheduled afterward.
This is a challenge across all industries and sectors, not just maintenance.
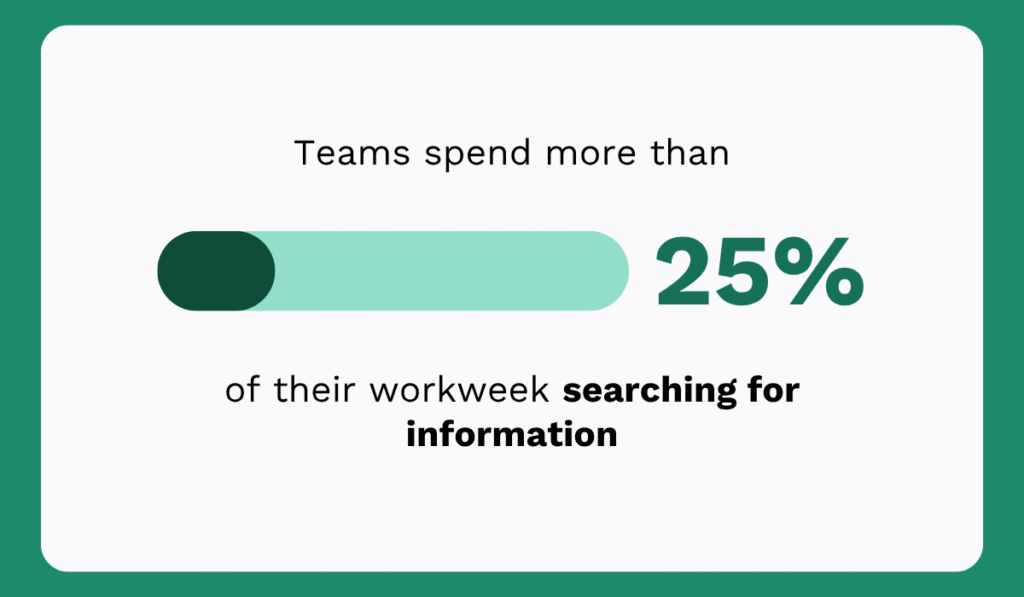
Atlassian’s State of Teams 2025 report found that teams spend more than 25% of their workweek searching for information.
In a typical 40-hour workweek, that’s the equivalent of spending about 10 hours, more than a full workday every week, just looking for information needed to complete tasks.
For maintenance teams, this lost productivity can appear as technicians searching for equipment manuals, previous repair records, asset details, or failure history instead of performing maintenance work.
The consequences extend beyond wasted technician hours.
For example, when a technician spends even 20 or 30 minutes searching for missing information during an urgent repair, the delay can:
Slow production recovery
Increase operational costs
Extend equipment downtime
Every minute spent chasing information is a minute taken away from restoring equipment and keeping operations running efficiently.
The trouble starts when that backlog grows beyond what your team can realistically manage.
An excessive backlog means maintenance tasks continue to accumulate faster than they can be completed.
Over time, maintenance requests pile up, work orders remain unassigned, and lower-priority tasks are repeatedly deferred, with no one tracking how long they’ve been waiting.
Many maintenance professionals consider a backlog of roughly two to four weeks to be healthy because it provides enough planned work to keep technicians productive without overwhelming the team.
If your backlog consistently exceeds that range, it’s a strong indicator that maintenance demand is outpacing available resources or that work isn’t being managed effectively.
Once your backlog grows beyond a healthy level, maintenance teams naturally focus on the most urgent work, leaving lower-priority repairs and preventive maintenance tasks waiting.
Over time, those seemingly minor issues can develop into larger failures that require longer downtime, additional resources, and more expensive repairs.
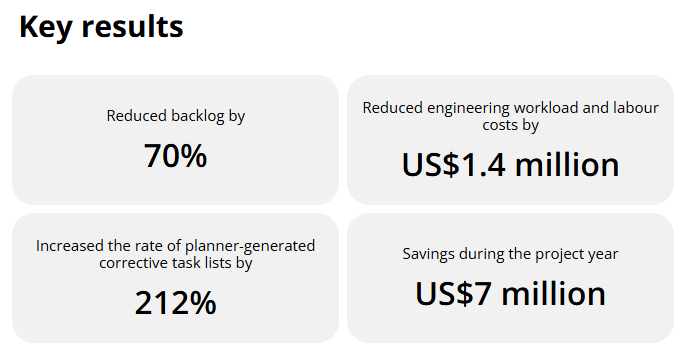
A good example comes from this large offshore energy company that struggled with an excessive maintenance backlog across its operations.
As work orders accumulated, maintenance planning became increasingly difficult, making it harder to prioritize maintenance activities and deploy resources effectively.
After redesigning its work management process and strengthening its planning and scheduling practices, the company reduced its maintenance backlog by 70%, improving operational performance and responsiveness.
While not every organization will experience a backlog at this scale, the case illustrates how an unmanaged backlog can gradually erode maintenance efficiency until it becomes a significant operational challenge.
An unmanaged backlog also puts pressure on maintenance teams.
Faced with a constant queue of overdue work orders, technicians may rush jobs, shift priorities frequently, or focus almost exclusively on emergency repairs.
This reactive cycle makes it harder to complete planned maintenance activities and maintain long-term equipment reliability.
The impact extends beyond the maintenance department.
A growing backlog can make it harder for managers to accurately understand the true condition of their assets, forecast workload, and allocate resources effectively.
When too many unresolved issues accumulate, the maintenance team is no longer managing the backlog; the backlog is managing the team.
Poor Performance Visibility
You can’t improve what you can’t see.
Yet many maintenance teams struggle to measure performance because work order data is incomplete and inaccurate, reporting is inconsistent, or key performance metrics are missing altogether.
Without reliable data, managers are forced to make decisions based on assumptions rather than evidence.
In maintenance, this plays out in familiar ways.
A manager might assume the team is keeping up with planned maintenance because no one has raised concerns, only to discover during a budget review that reactive repairs have quietly overtaken preventive maintenance for months.
Inaccurate reporting often causes managers to overestimate how much planned work is being completed and underestimate the time lost to delays, administrative work, and recurring failures.
Ricky Smith, Vice President of World Class Maintenance, a maintenance and reliability training and consulting organization, summarizes this problem well:
Poor visibility also leads to poor resource allocation.
Without accurate, real-time data, decisions about staffing, scheduling, inventory, and budgets become educated guesses.
A manager might assign additional technicians to what appears to be an overloaded area when the real issue is that work orders are sitting unassigned or awaiting approval.
Likewise, recurring equipment failures may continue to receive reactive repairs because incomplete maintenance records hide the underlying pattern.
A metric has little value if it doesn’t drive action.
Reports become little more than paperwork, and recurring problems remain hidden when performance visibility is poor.
Equipment failures and emergency repairs are an inevitable part of running a manufacturing operation.
The problem arises when reactive maintenance becomes the norm rather than the exception.
When maintenance teams spend most of their time responding to emergencies, it often reflects deeper issues elsewhere in the maintenance operation.
Instead of preventing failures before they occur, technicians are forced into a constant cycle of responding to them.
However, reactive maintenance is more common than many organizations realize.
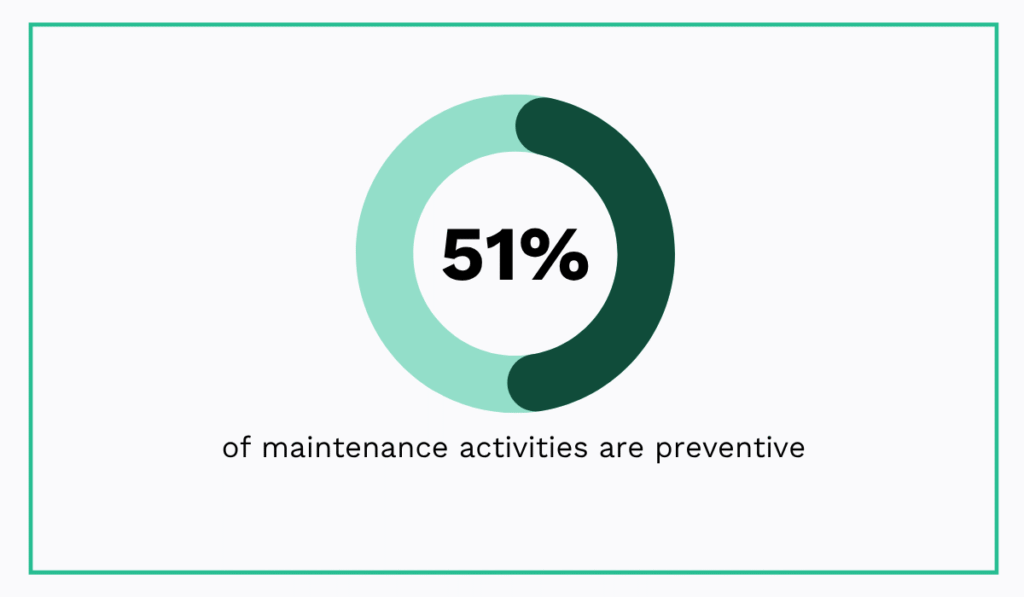
A McKinsey survey found that, on average, only 51% of maintenance activities are preventive, suggesting many manufacturers still devote a significant share of their maintenance effort to unplanned work.
Rather than following a proactive maintenance strategy, many teams continue to spend much of their time reacting to equipment failures after they’ve already occurred.
The financial consequences can be substantial.
Organizations that rely heavily on reactive maintenance often experience more frequent and costly unplanned outages.
According to ABB’s 2023 Value of Reliability survey, the typical industrial business loses about $125,000 for every hour of unplanned downtime.
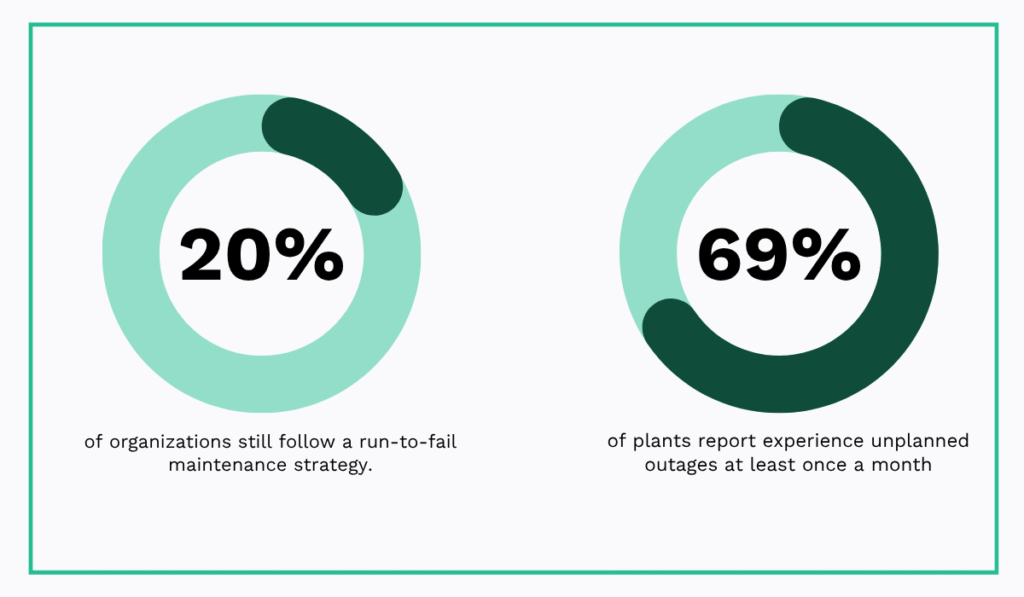
Despite these costs, the survey also found that one in five organizations still follow a run-to-fail maintenance strategy, while 69% report experiencing unplanned outages at least once a month.
Equipment allowed to operate with unresolved defects or deferred maintenance presents greater safety risks to both operators and maintenance personnel.
Minor issues left unaddressed can escalate into major failures that:
Disrupt production
Damage equipment
Create hazardous working conditions
Verve Viitanen, Head of Global Customer Care and Support at ABB Motion Services, reinforces the value of a proactive approach:
Reactive maintenance will always be part of manufacturing.
The goal isn’t to eliminate emergency work, but to ensure it remains the exception rather than the strategy.
Modern CMMS: One Tool that Solves All These Challenges
The work order challenges we’ve covered are rarely isolated problems.
Incomplete work orders, growing backlogs, poor visibility, and reactive maintenance often reinforce one another, creating a cycle that’s difficult to break.
A modern computerized maintenance management system (CMMS), like WorkTrek, helps break that cycle by bringing structure, consistency, and visibility to every stage of the work order process.
It provides a centralized platform where maintenance requests, work orders, asset history, preventive maintenance schedules, inventory records, and performance data all live in one place.
That said, software alone isn’t a silver bullet.
Success still depends on:
Well-defined workflows
Clear responsibilities
Consistent execution
A CMMS provides the tools to support those processes, but it doesn’t replace them.
When paired with strong maintenance practices, however, it enables teams to execute those processes more consistently and efficiently.
The process starts with better work requests.
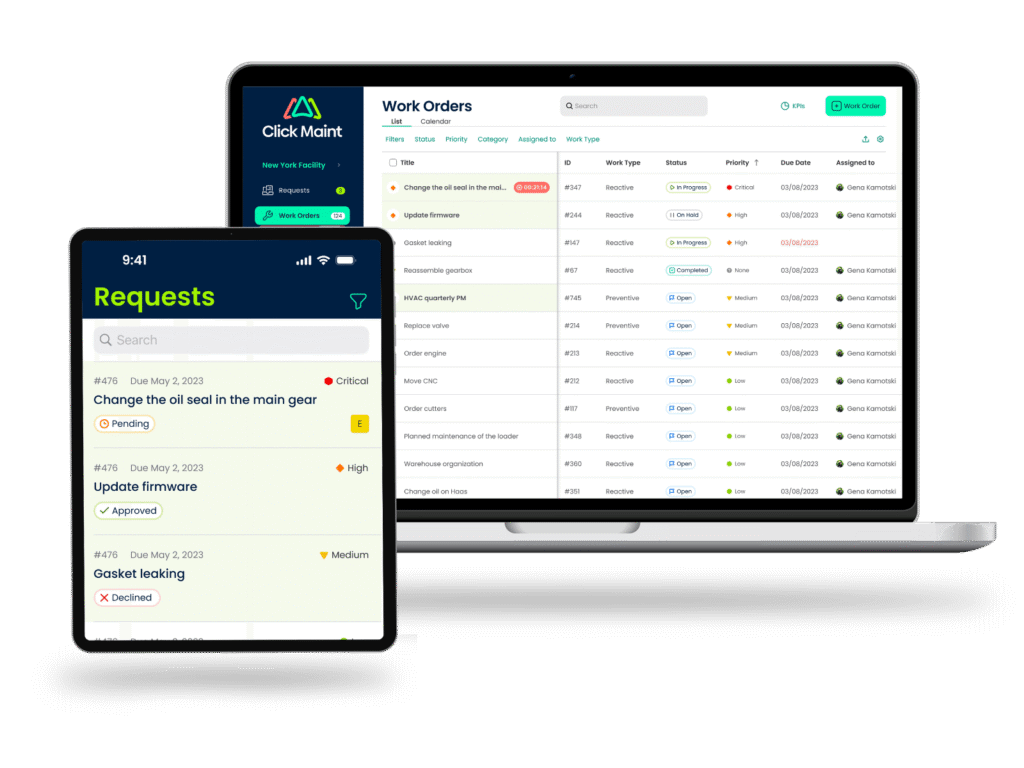
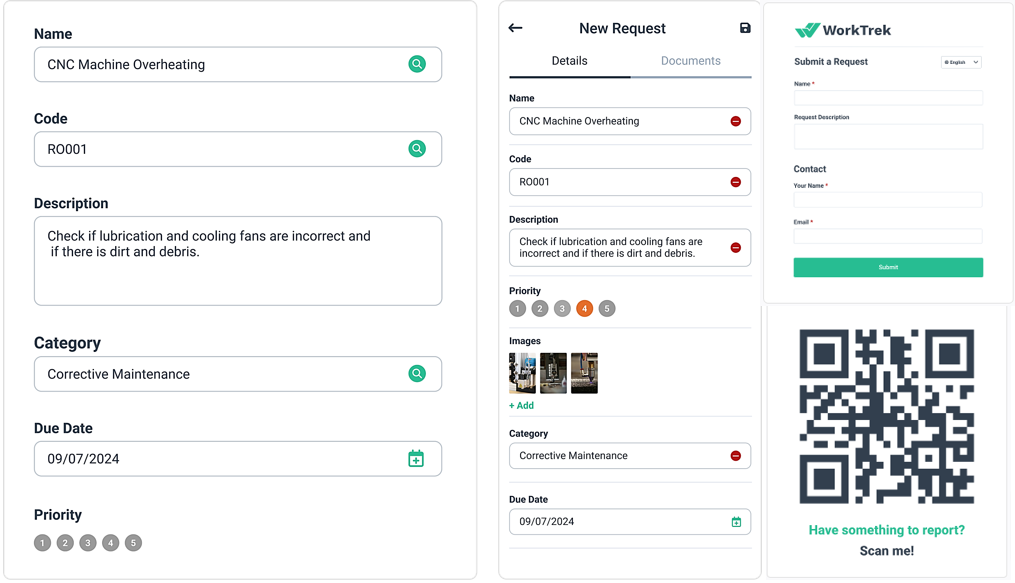
To reduce incomplete work orders and eliminate information gaps, WorkTrek’s Work Request Management feature gives employees a standardized way to submit maintenance requests.
By capturing essential information such as asset details, issue descriptions, priority levels, and supporting attachments upfront, technicians spend less time chasing missing information and more time resolving the problem.
Once a request is approved, it becomes a structured work order.
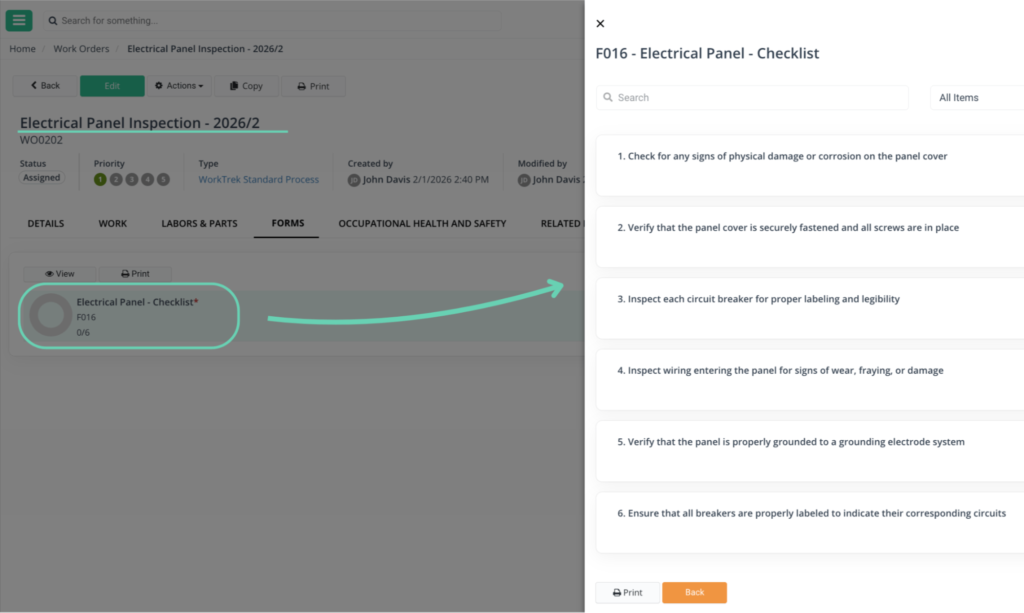
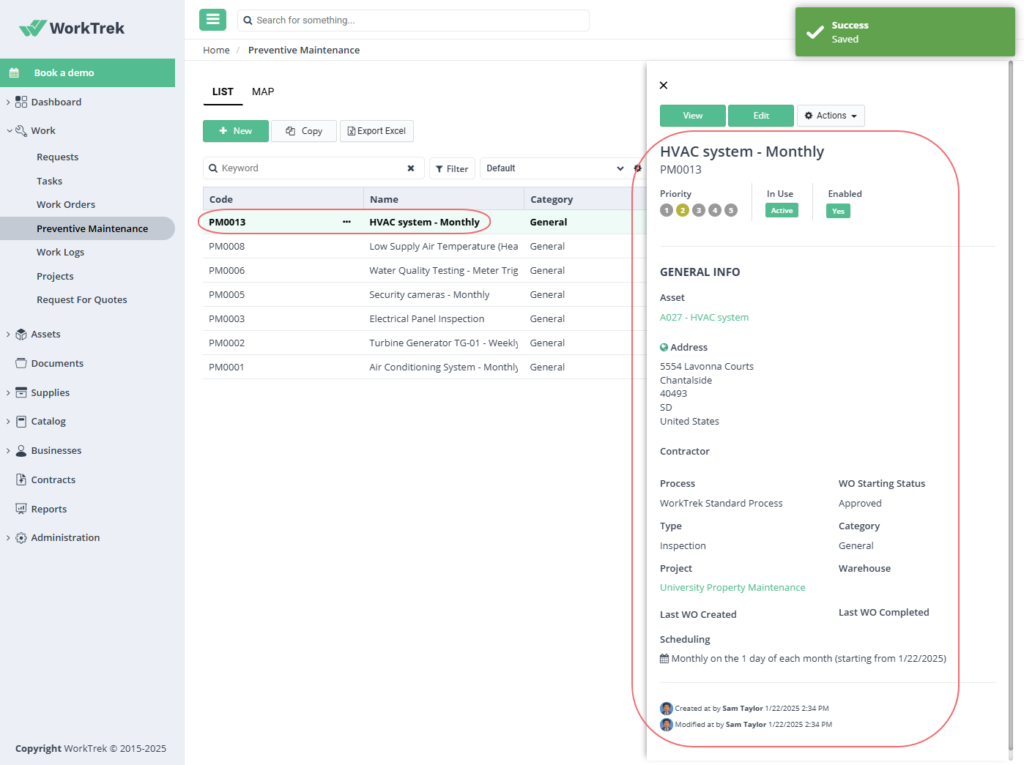
WorkTrek’s Work Order Management feature centralizes everything technicians and supervisors need, including asset history, assigned personnel, labor hours, parts used, checklists, notes, and completion status.
With everyone working from the same up-to-date information, technicians arrive better prepared, supervisors gain real-time visibility into work progress, and managers can make decisions based on accurate data rather than assumptions.
Effective planning also depends on having the right parts available when work begins.
WorkTrek’s Parts Inventory Management feature gives maintenance teams real-time visibility into inventory levels, parts usage, and reorder points.
This helps planners confirm that required materials are available before scheduling work, which reduces delays caused by missing inventory, emergency purchases, or last-minute trips to the storeroom.
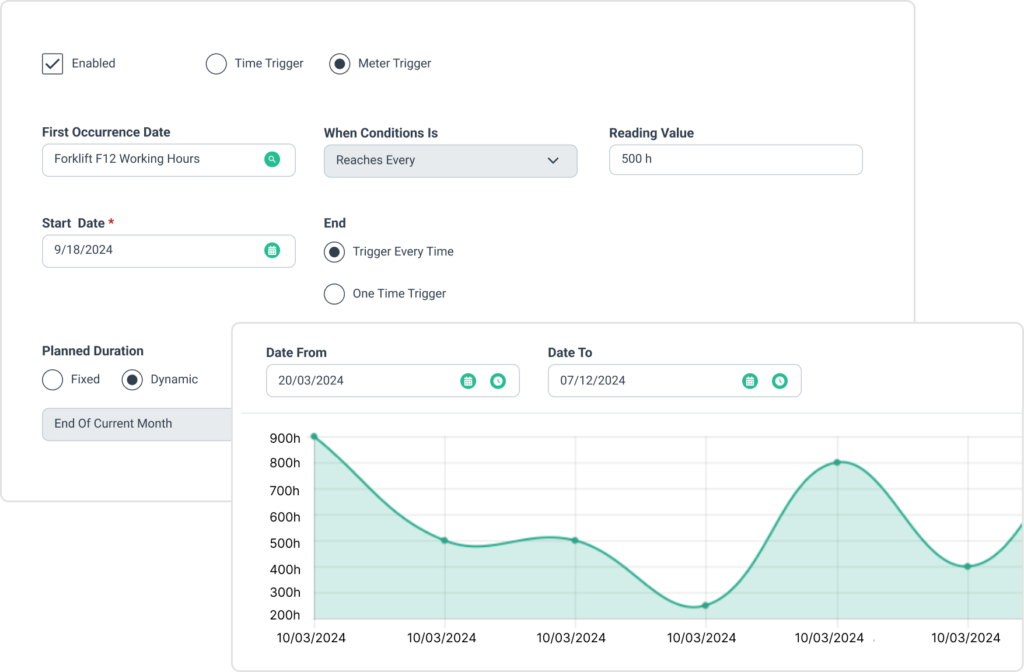
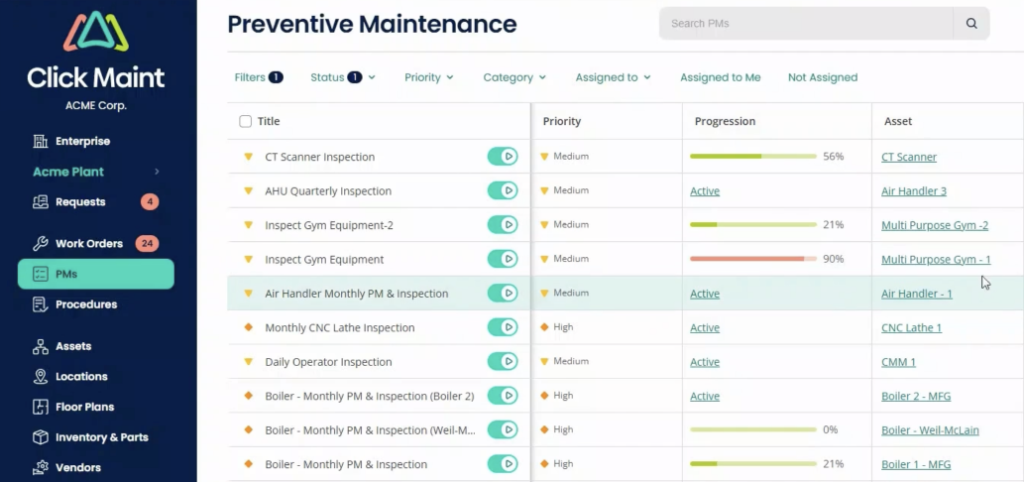
From there, Preventive Maintenance capabilities help shift maintenance from reactive to proactive.
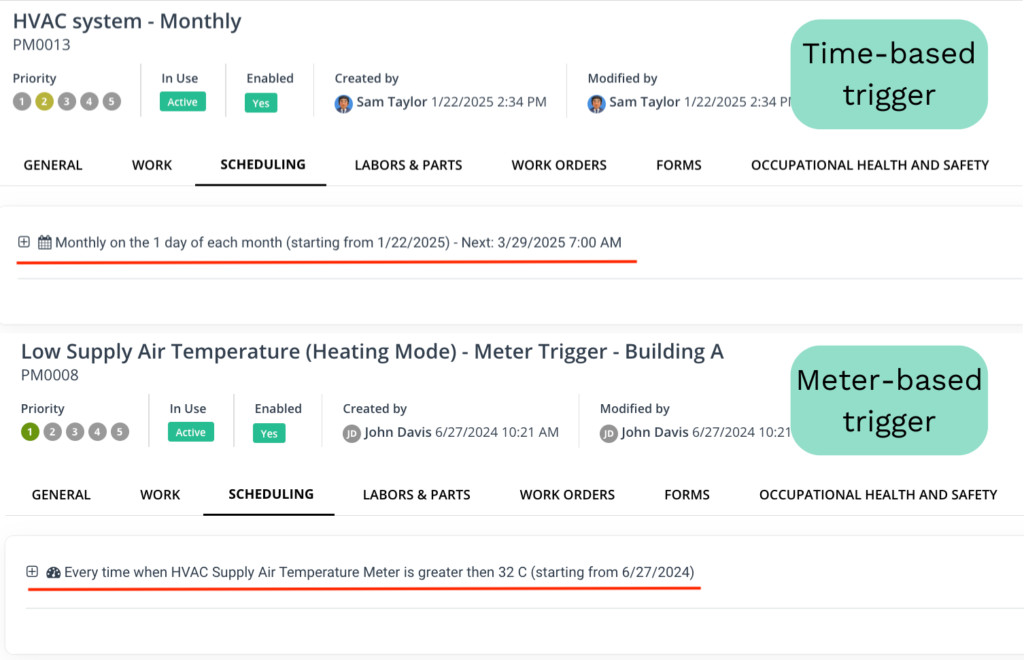
WorkTrek can automatically generate recurring work orders based on time intervals, equipment usage, or meter readings, making it easier to schedule routine maintenance before equipment problems escalate into costly failures.
The clarity of data enables maintenance teams to consistently complete preventive work and reduce their dependence on emergency repairs.
Ultimately, a CMMS doesn’t improve maintenance simply by digitizing work orders.
It improves maintenance by making the entire work order process more structured, visible, and accountable.
Combined with well-defined processes and consistent user adoption, WorkTrek provides maintenance teams with the foundation they need to reduce reactive work, manage the backlog more effectively, improve performance visibility, and keep critical assets operating reliably.
Conclusion
The work order is the backbone of your entire maintenance operation.
When it’s ineffective, your team struggles to respond quickly, plan work effectively, allocate resources efficiently, and keep critical assets operating reliably.
Many common maintenance challenges can often be traced back to weaknesses in the work order process.
Improving that process means making sure every maintenance activity starts with the information needed to complete the job successfully.
A modern CMMS like WorkTrek supports that effort by establishing a consistent workflow and providing your team with a single source of truth for maintenance information.
But software is only part of the equation.
Lasting improvements come from the people and processes behind it, with technology helping your team execute their tasks consistently.
How to Build an Effective Maintenance Work Order Process: A Step-by-Step Guide
Key Takeaways:
Manufacturers lose an estimated $1.4 trillion annually to unplanned downtime.
Over one-third of employees lose 40+ hours yearly due to unclear communication.
Tracking KPIs ensures a measurable, continuously improving upkeep operation.
Most maintenance teams don’t fail for lack of skill. They fail because of inefficient work order processes.
A work order arrives with insufficient detail, no one clarifies it, and a technician shows up to the job unprepared.
Or five people request the same repair through five different channels, and two technicians end up doing the same work on the same day.
These problems rarely seem significant at first. However, they accumulate until the backlog grows, costs climb, and reactive firefighting becomes the default.
This guide walks through five concrete steps for building a work order process that addresses these problems and actually works.
Map Your Current Process
Before improving your work order workflow, you first need to understand how work gets done right now.
That’s why maintenance process mapping is the first step to building an effective maintenance work order process.
It enables you to uncover and address hidden inefficiencies, such as communication gaps, poor documentation practices, or delays caused by unclear responsibilities.
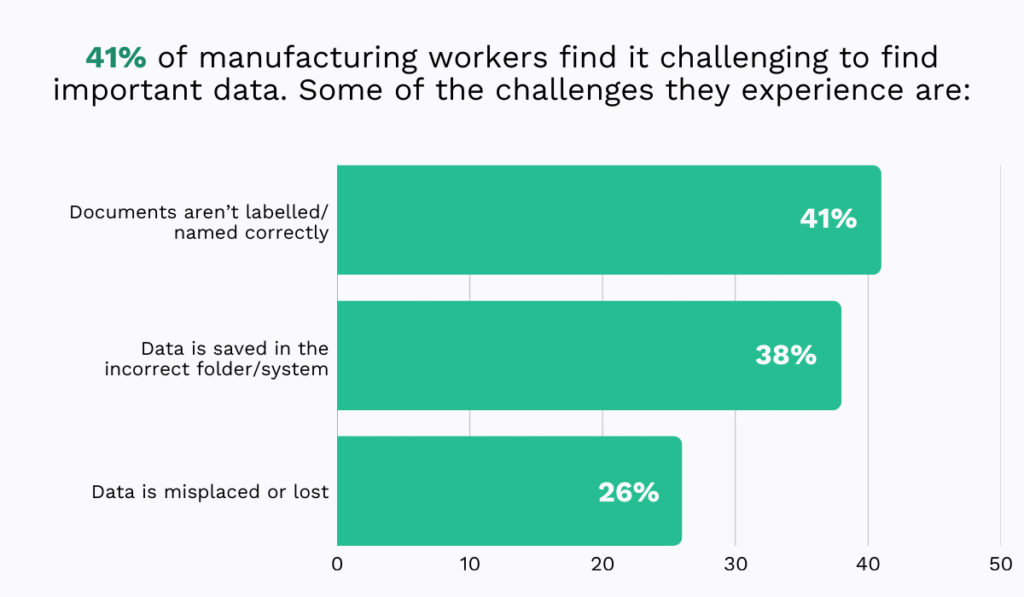
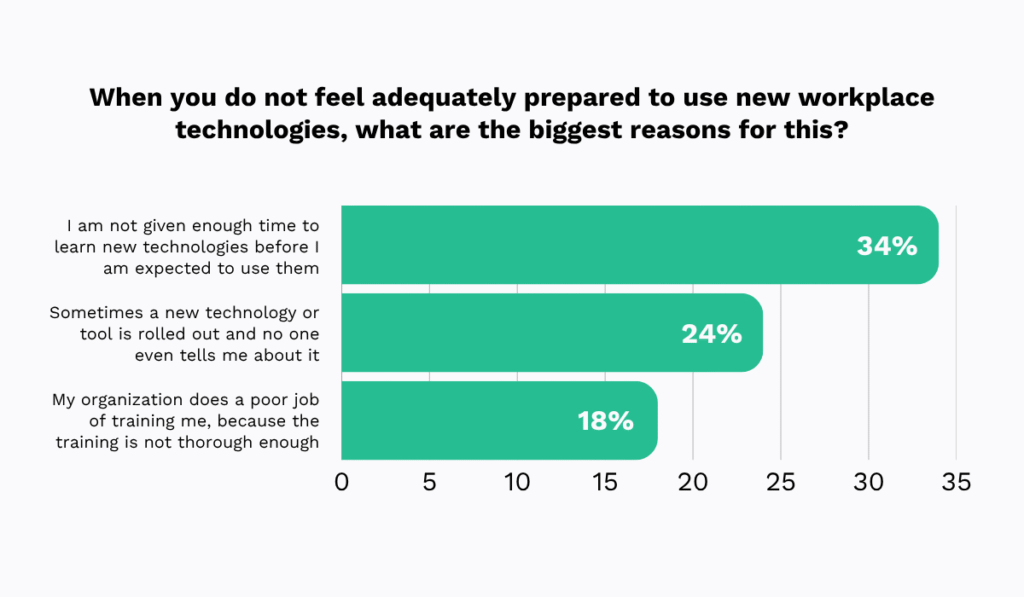
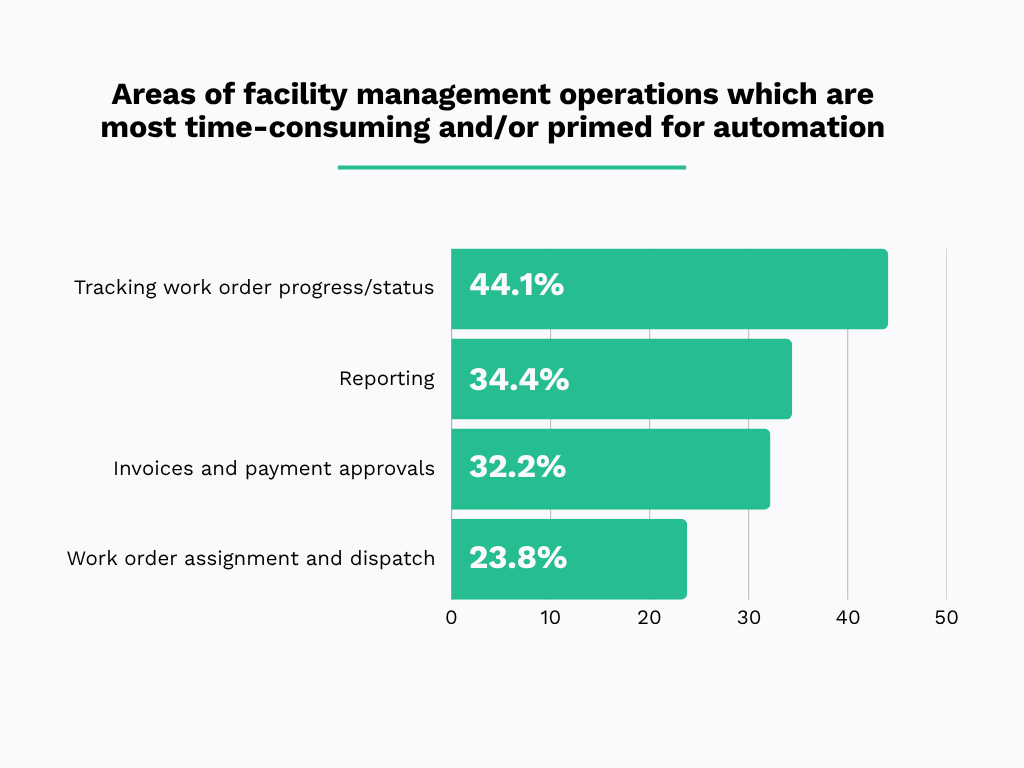
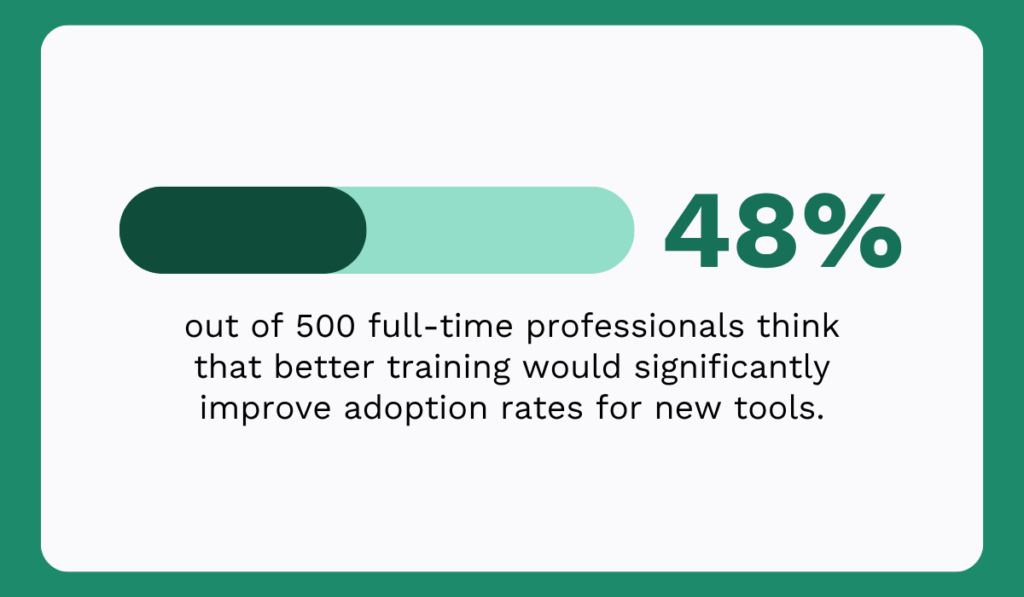
For instance, the 2021 EDH Technology survey shows that 41% of manufacturing workers struggle to find the information they need.
In a maintenance department, that could mean looking for the latest work order, chasing approvals, or trying to understand who is responsible for the next step.
Those seemingly small delays quickly add up across hundreds or even thousands of work orders every year.
The easiest way to uncover those inefficiencies is to trace a single work order from the moment a problem is reported until the job is officially closed.
Ask questions like:
How was the issue reported in the first place?
Who received the request, and how long did it sit before someone responded?
Who decided the priority level?
How were labor hours, spare parts, and downtime recorded?
How was the completed work documented and verified?
The answers often reveal hidden gaps in your operations.
Break down every step exactly as it happens today, even if the process looks messy.
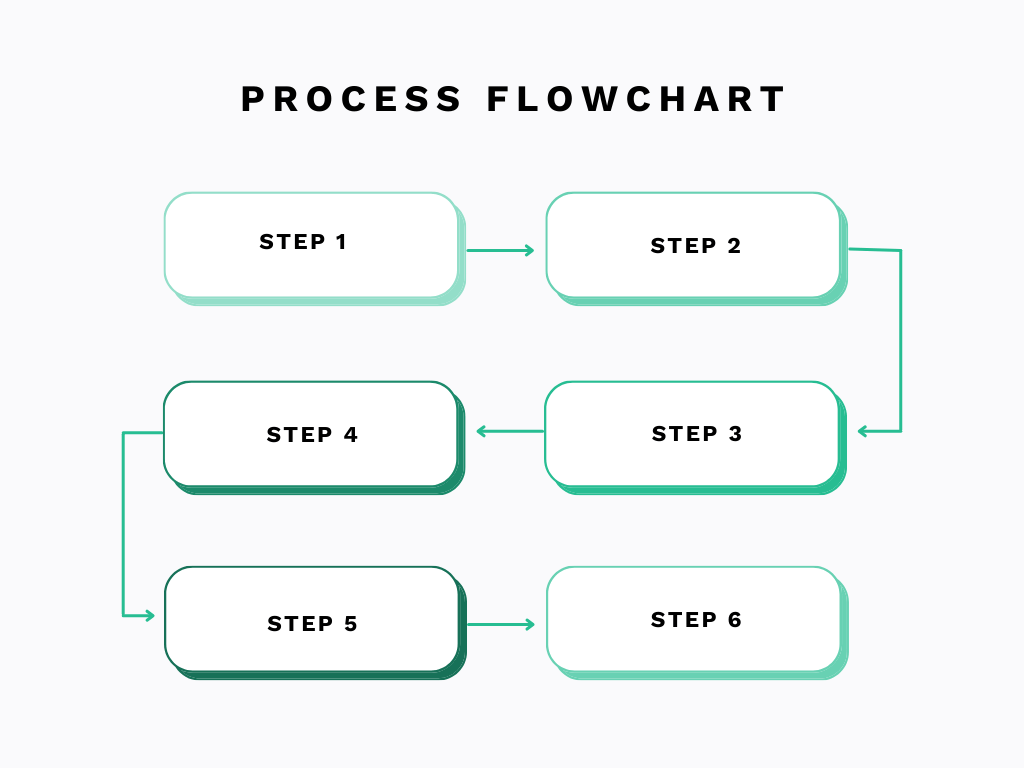
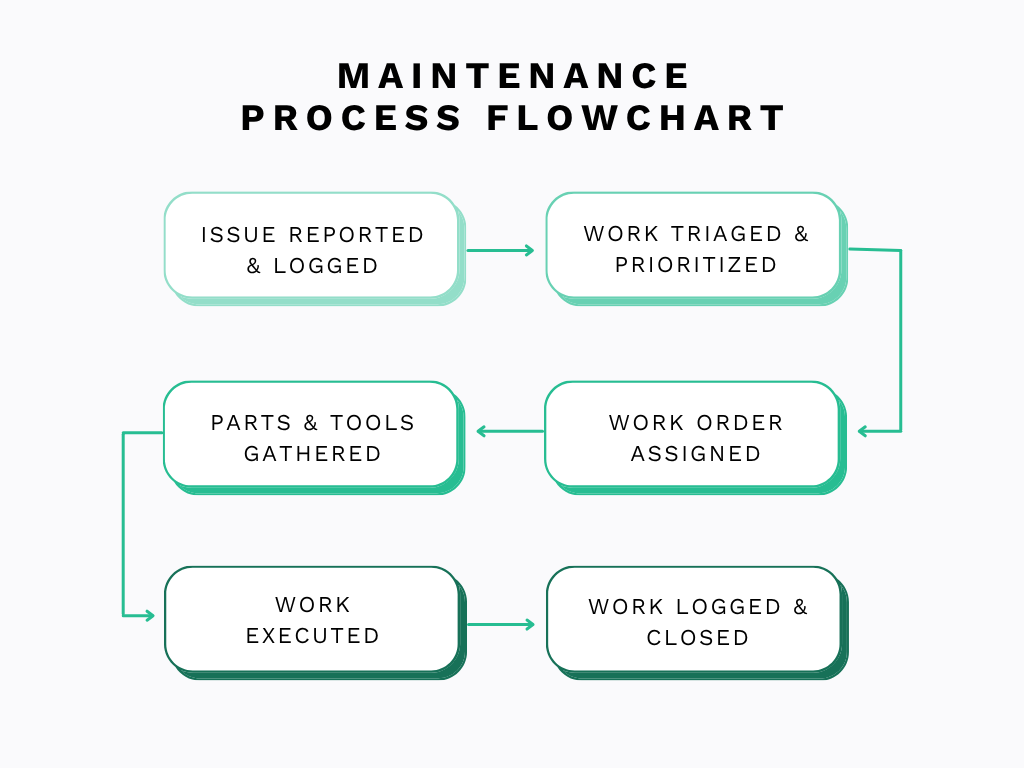
A simple flowchart, like the one you see below, is often enough to get started.
Begin with the maintenance request and map every handoff, approval, assignment, repair, inspection, and close-out.
You will quickly discover that many delays may happen outside your documented process.
Phone calls, hallway conversations, sticky notes, personal spreadsheets, and verbal approvals often become unofficial systems for managing maintenance work.
In the end, moving those habits into a CMMS will not solve the problem.
You will simply digitize the confusion.
Mapping your existing workflow first helps you identify those weaknesses before they become permanent.
Standardize Work Order Intake
Once you map your process, you need to improve how data comes in.
If one technician receives maintenance requests by phone, another by email, and someone else logs them in a spreadsheet, you have a potential problem before the work even begins.
Every request follows a different path, which means information gets recorded differently or, worse, not at all.
Over time, this can create:
Inconsistent data
Duplicate work orders
Missing asset history
Delayed repairs
A technician might receive a phone call about a leaking pump but forget to log it. Someone else might update a spreadsheet but omit critical details like the asset ID or priority level.
A tragic example of why standardization matters occurred in 2010 at DuPont’s Belle facility in West Virginia.
A braided steel hose connected to a one-ton phosgene tank suddenly ruptured, releasing a highly toxic gas. A veteran operator was exposed to the leak and died the following day.
This is a dangerous way to run a maintenance team.
You need strict rules for what constitutes a high-priority task. Otherwise, you expose your operation to the biggest productivity killer of them all: unplanned downtime.
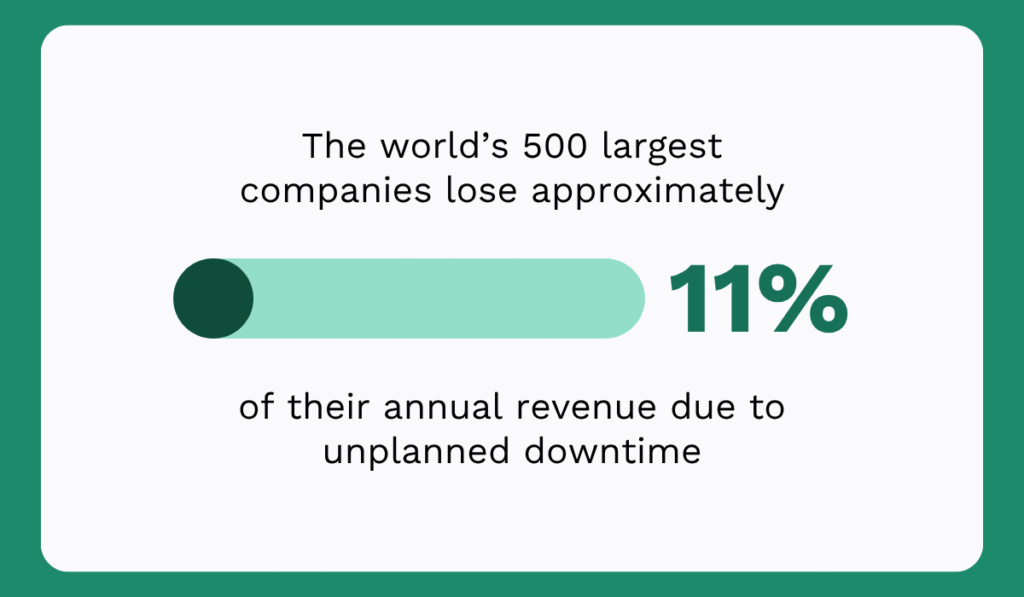
According to Siemens’ 2024 True Cost of Downtime report, the world’s 500 largest manufacturers lose an estimated $1.4 trillion every year to unplanned downtime, roughly 11% of their annual revenue.
One of the simplest ways to reduce maintenance costs is to establish work order prioritization rules.
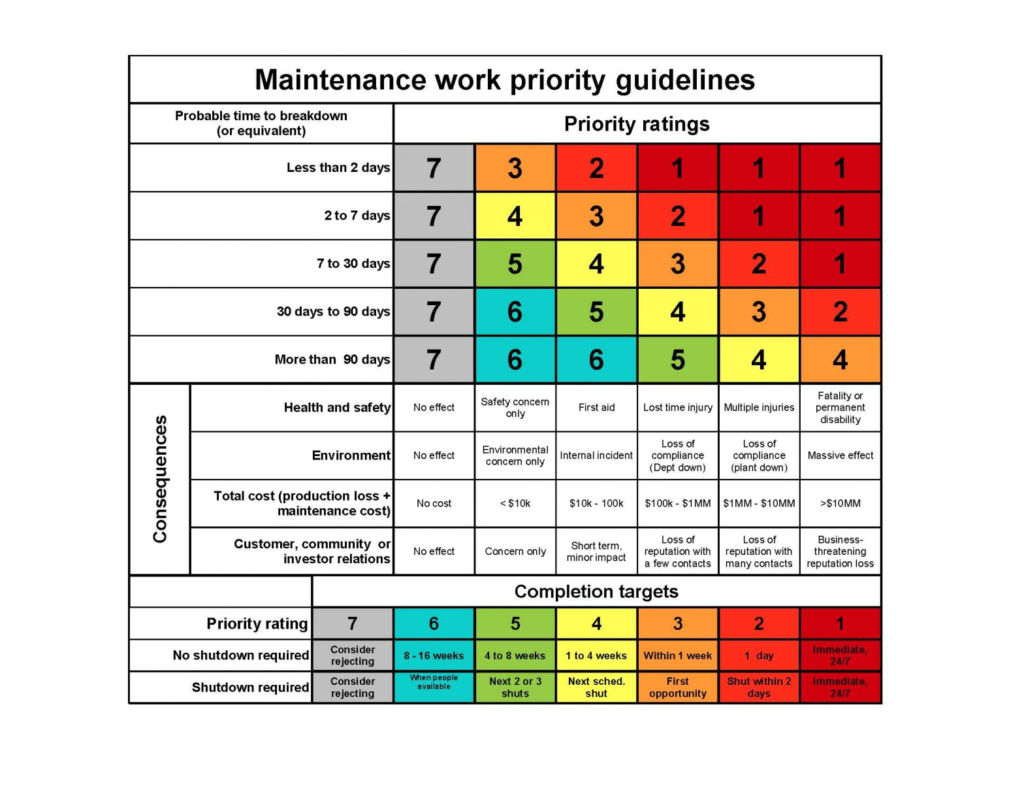
Most organizations evaluate work orders using a tiered approach.
Safety risks always come first, followed by regulatory or environmental compliance, asset criticality, operational impact, and finally routine maintenance.
These elements are typically all laid out in a matrix that combines likelihood with the severity of the issue, as shown below:
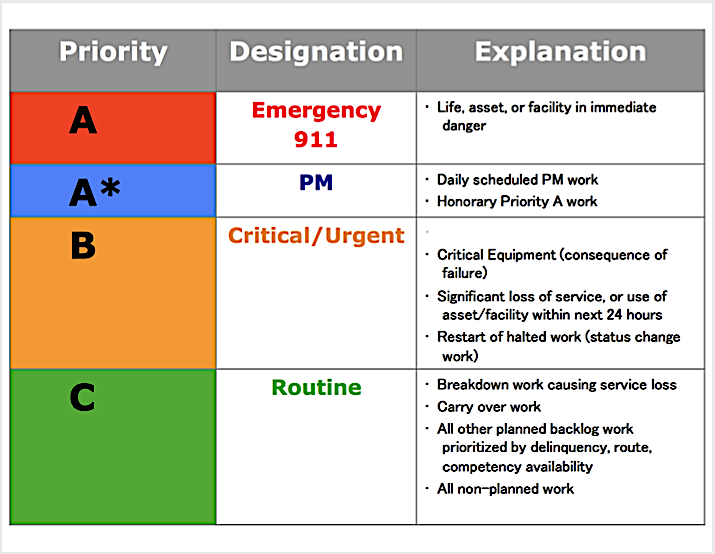
Or you could also simplify decision-making by assigning priority levels such as A, A*, B, and C, where each level represents a predefined response based on risk and business impact, like so:
This also improves workload planning, allowing managers to see how many high-priority tasks are waiting and adjust staffing before bottlenecks develop.
Without prioritization rules, your team may always be reactive or never get ahead of the preventive maintenance schedule.
Establishing these rules takes a little time up front, but it saves hundreds of hours later.
Below, you can watch an informative guide on maintenance KPIs by Ed Surber, Founder & Head of Operations at PIE Electric Inc., an electrical services provider:
Contrary to popular belief, maintenance KPIs aren’t only for massive refineries or manufacturing plants.
Every facility, from schools and hospitals to warehouses and commercial buildings, can use maintenance metrics to identify bottlenecks and continuously improve operations.
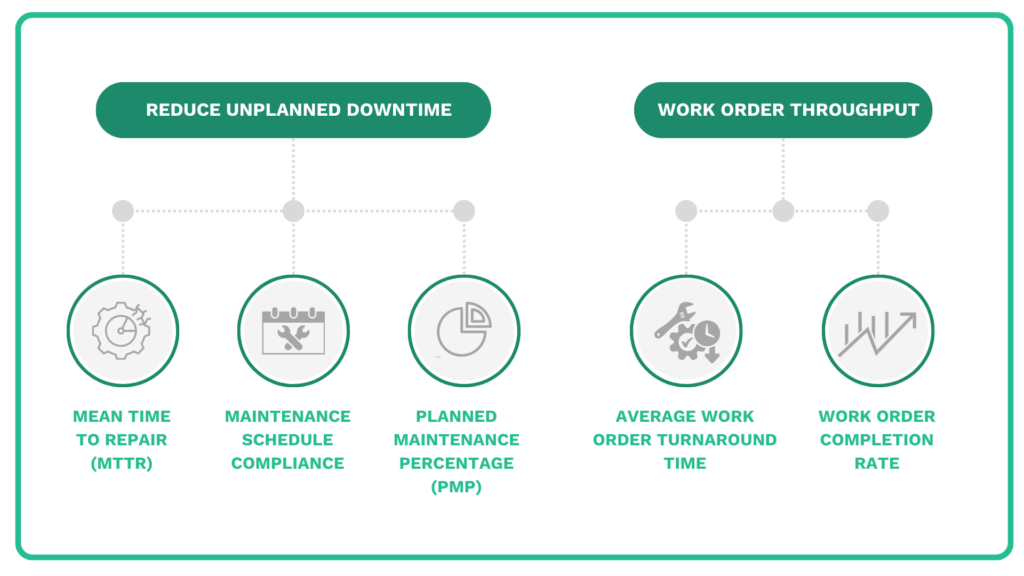
Here are some of the most valuable KPIs your maintenance team can monitor:
KPI
Why it matters
What does it tells you
Mean Time to Repair (MTTR)
Measures how quickly assets are restored after failure.
High MTTR may indicate inefficient troubleshooting, poor spare parts availability, or inadequate technician training.
Preventive Maintenance (PM) Compliance
Tracks the percentage of scheduled PM tasks completed on time.
Low compliance often signals resource shortages, unrealistic scheduling, or excessive reactive work.
Work Order Completion Rate
Measures how many assigned work orders are completed within the planned period.
Helps identify backlog growth and overall maintenance productivity.
Planned vs. Reactive Maintenance Ratio
Compares planned maintenance against emergency repairs.
A higher percentage of planned work generally indicates a more mature and proactive maintenance program.
Maintenance Backlog
Measures outstanding maintenance work waiting to be completed.
A growing backlog may indicate understaffing, poor prioritization, or recurring asset failures.
Schedule Compliance
Tracks how closely technicians follow the planned maintenance schedule.
Reveals whether daily maintenance plans are realistic and achievable.
These metrics tell you not only how quickly your team fixes equipment but also how effectively it prevents failures in the first place.
For example, if your MTTR continues to increase, the problem may not be your technicians at all.
It could indicate delays in locating spare parts, lengthy approval processes, or poor work order planning.
Likewise, consistently low PM Compliance often suggests your team is overloaded with reactive work or scheduling more preventive maintenance than available resources can realistically support.
Looking at multiple KPIs together provides even greater insight. In fact, Reliable Magazine estimates plants track about 30 metrics.
However, KPIs aren’t just for your supervisors to track. Technicians should also be able to access and monitor them.
When teams understand how their work contributes to larger operational goals, they are more likely to identify inefficiencies, suggest improvements, and take ownership.
Track these metrics consistently, review them regularly, and look for trends instead of isolated numbers.
Over time, better visibility replaces guesswork, allowing your maintenance team to spend less time firefighting and more time building a reliable, proactive maintenance operation.
Develop Standard Operating Procedures
Standard Operating Procedures (SOPs) document exactly how a maintenance task should be performed.
You can see a template for one such document below:
These documents are more important than many realize.
Without one, two technicians are more likely to repair the same asset using completely different methods.
That inconsistency can lead to safety risks, longer repair times, and unreliable maintenance records.
This is why industries such as manufacturing, oil and gas, chemicals, pharmaceuticals, healthcare, utilities, aviation, and construction rely heavily on SOPs.
Another great advantage of well-crafted SOPs is that they preserve institutional knowledge.
Experienced technicians eventually retire, change jobs, or move into leadership roles. SOPs allow their expertise to remain part of your maintenance program.
Digital SOPs make everything even easier and more accessible.
Rather than updating paper manuals or emailing revised instructions, maintenance teams can instantly publish the latest version.
If a safer inspection method, improved repair technique, or new regulatory requirement emerges, everyone can access the same updated procedure immediately.
Essentially, your SOPs evolve alongside your equipment, workforce, and maintenance practices.
Conclusion
Improving your maintenance work order process does not happen overnight, but every improvement builds on the last.
A well-defined workflow helps eliminate confusion, ensures work is prioritized correctly, and gives technicians the information they need to complete jobs efficiently.
Combined with measurable KPIs and standardized procedures, your work order process becomes a reliable system for driving continuous improvement.
The sooner you build that foundation, the easier it becomes to reduce downtime and keep maintenance operations running smoothly.
How to Use Digital Tools to Streamline Maintenance Workflows
Key Takeaways:
Mapping out upkeep processes ensures that a new tool fixes problems rather than repeating them.
Defining clear KPIs before committing to a system helps avoid buyer’s remorse.
Centralizing scattered maintenance data into one system creates a single source of truth.
Training your team ensures a system gets used more consistently and effectively.
Are you currently looking to implement a digital tool into your maintenance operations?
These systems can do a lot for your team, from cutting downtime to helping keep better records.
But buying a feature-rich system is not enough on its own.
Without a few important steps taken beforehand, even a capable tool can fall short.
That’s why this article will walk you through seven steps for successfully using digital tools to improve your maintenance workflows.
1. Map Your Existing Processes
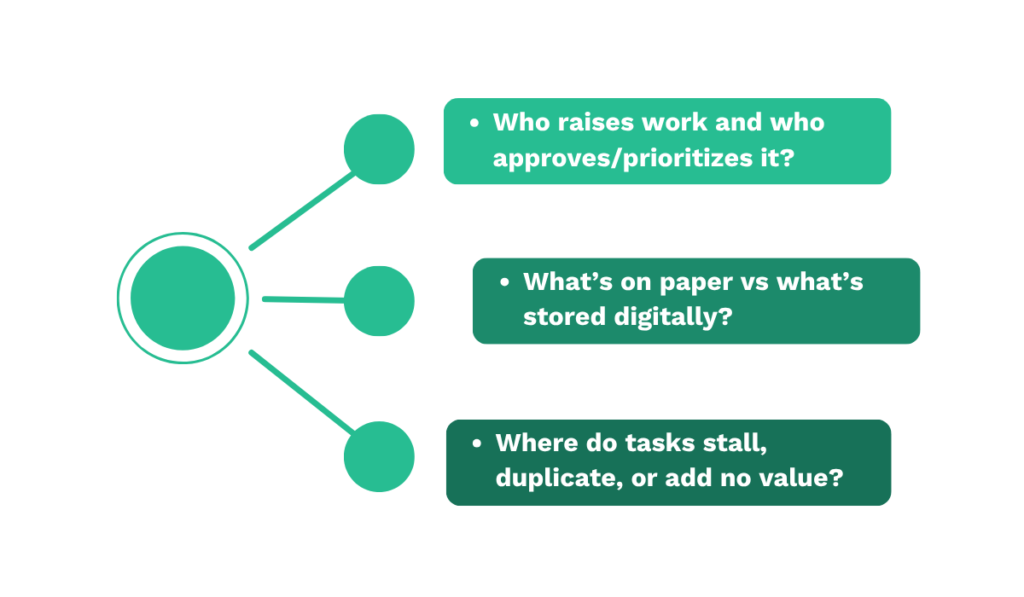
You need a clear picture of how work flows across your teams and sites before bringing in any digital tool.
Audrey Van de Castle, senior director of operational excellence technology at Stanley Black & Decker, talked on this topic on a recent podcast.
She explained that adding a digital solution on top of an ineffective workflow is rarely the right move.
Answering these for every workflow surfaces the gaps and handoffs that a digital tool will later need to support.
Once this is done, you’ll have a documented baseline of how your maintenance runs today, which sets up every decision that follows.
2. Define What You Want the New Tool to Achieve
Once you have your processes mapped, the following step is to figure out how a digital tool fits into them and what you want it to achieve.
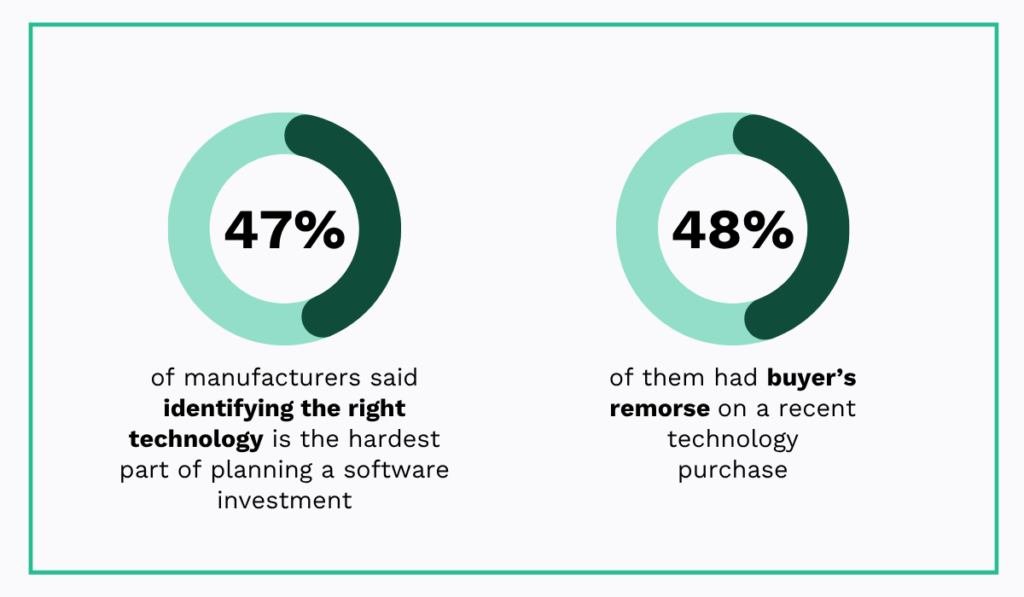
This step matters more than it might seem, because choosing the right software is something many teams struggle with.
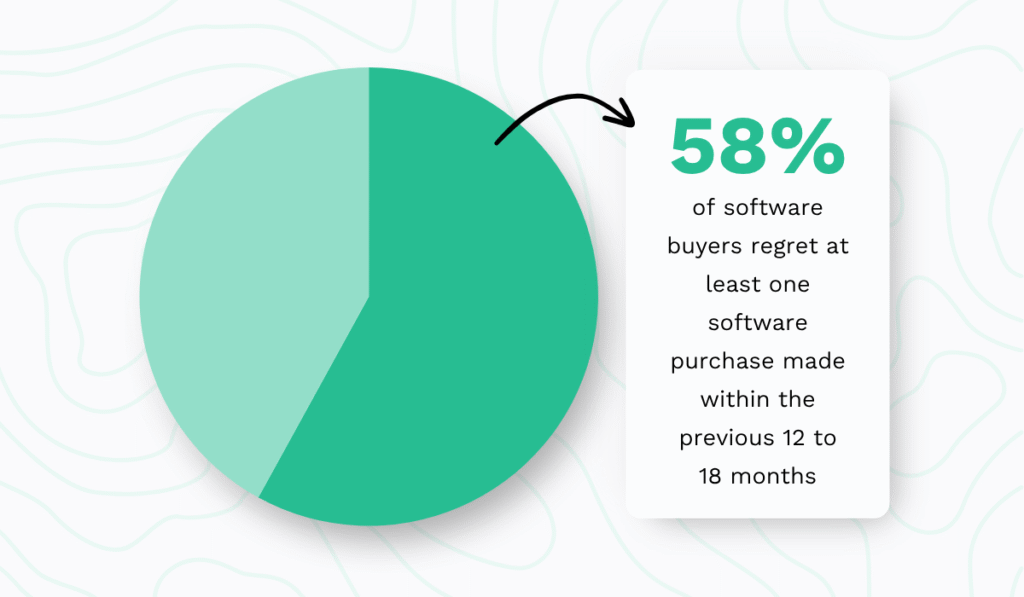
In fact, according to data from Capterra, almost half of the surveyed manufacturers had trouble identifying the right solution for their needs, and many later regretted their purchase.
If that same tool also pushes you toward your other goals, even better.
In your own operations, you might need one highly specific system that is focused on a single workflow, or something more general that covers many use cases.
The table below maps some common goals to the tool types that typically fit them best.
Goal
The tool type that fits
Cut unplanned downtime
CMMS with strong PM scheduling
Stop running out of parts
Parts & inventory management system
Digitize inspections & checklists
CMMS with mobile app, digital forms app
Stay audit- and compliance-ready
CMMS with checklists & audit trails
See across multiple sites
Enterprise CMMS or EAM
Predict failures before they happen
CMMS with condition monitoring, IoT platform
As you can see, CMMS appears repeatedly in this table because it is generally the best digital tool for streamlining maintenance overall.
Take WorkTrek as an example, our own cloud-based CMMS built to manage maintenance work in one place.
It covers the core areas most teams need, with features like:
Work order management
Preventive maintenance scheduling
Inventory and parts management
Digital checklists and inspections
A mobile app for technicians
Dashboards and reporting
In practice, with WorkTrek, a request can come in, turn into a work order, get scheduled and assigned, then close with parts and history logged in the same system.
Ultimately, a CMMS system like this one supports many processes at once, which is what makes it a natural fit for streamlining maintenance workflows.
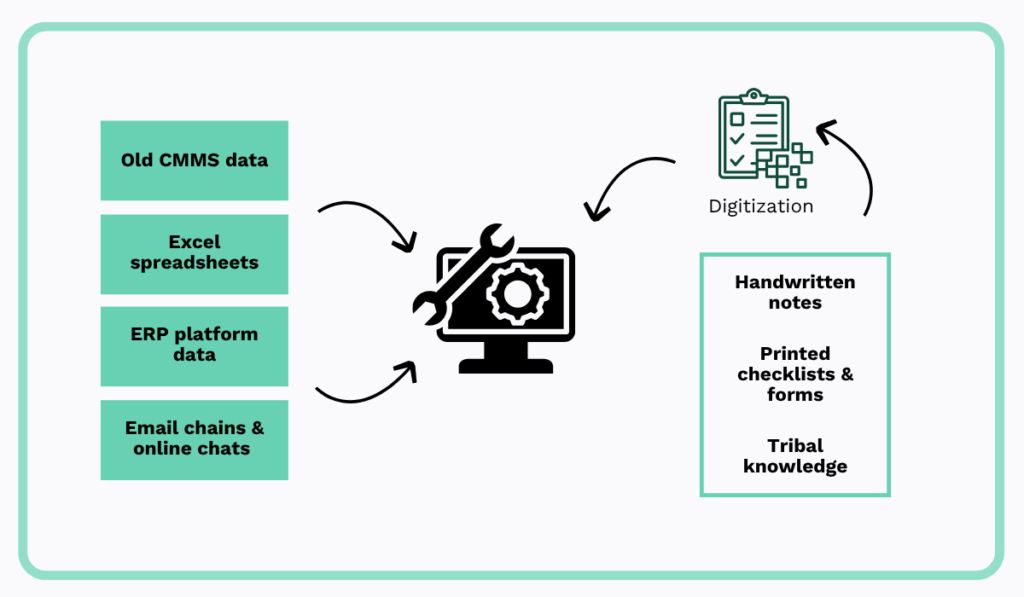
4. Centralize Data
Another major source of inefficiency in maintenance is fragmented information.
This simply means your maintenance data is stored in many separate places instead of one, so no one has the full picture.
It can happen for many reasons, from old habits to skipping shared processes and letting each person track work their own way.
Whatever the cause, the result is usually messy.
One Reddit thread captures this well, with the writer describing maintenance data spread across several digital systems or jotted down on paper, when it gets recorded at all.
Centralizing data that is already digital tends to be easier, especially if some standardization was followed along the way.
It usually involves organizing records from legacy systems and spreadsheets, then moving them into one place.
Physical data is a bit trickier to handle.
Handwritten notes and paper checklists need to be digitized and matched to the right assets before they are useful.
Then there is tribal knowledge, the undocumented knowledge that your technicians hold, which you will want to write down and store in the system while those people are still around.
The point is that this work has to be done for the rest of your digital effort to succeed.
Done well, it turns scattered records into data your whole team can trust.
5. Digitalize Only One Key Workflow First
Once your data is centralized, it can be tempting to digitize every workflow at once.
That is usually a mistake.
A better approach is to gradually introduce this digital change and start with one high-impact process.
In essence, you want to prove the system works to yourself and your team and refine your process before expanding.
Even without a dedicated change manager on staff, the lesson here is that a careful and well-planned rollout beats rushing.
For digital tools specifically, a gradual approach works best, so we suggest focusing on improving a single workflow first.
This can be a fairly simple process that lets you test the system in real conditions.
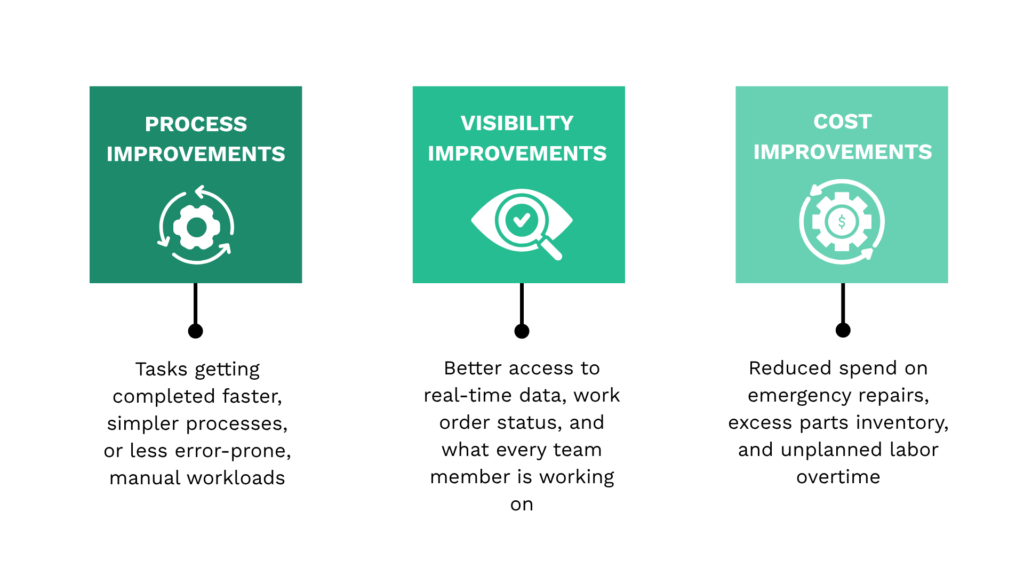
You have plenty to choose from, and even one work-order lifecycle has several points worth improving, like assignment automation, work order prioritization, mobile checklists, and forms…the list goes on.
No matter the workflow you choose, you want to consider specific types of improvement to aim for, with three key categories shown below.
To highlight one training tip, you want to keep it as realistic as you can.
Where possible, train people on the workflow you chose to digitize first, and have your more tech-savvy staff act as internal mentors who support others.
This gives everyone hands-on practice and a clear person to ask when questions come up.
Next, role-based onboarding also matters a lot when you are working with a feature-rich platform like a CMMS.
After all, not everyone needs to know every aspect of the system.
As an example, a technician might mainly learn about work orders and the mobile app, while a maintenance planner would focus more on scheduling and reporting features.
On that topic, Steven McKissick of MRI Software points out that the right system can make this learning and onboarding process easier, depending on how clean its interface and overall design are.
The purpose of these elements is to ensure anyone can pick up a procedure and carry it out the same way every time.
After all, when every technician uses the tool the same way, your workflows become smoother, and data reflects what is happening.
The digital tool you choose can take on a lot of this work for you.
For instance, a solid knowledge base, tied to features like work order management, can hold your step-by-step instructions right where the work happens.
You will still need to adapt and build on these over time, but the overall goal is to make them fit naturally into your wider maintenance workflows.
Done consistently, SOPs keep your data reliable and your whole team working the same way.
Conclusion
And that is the overall process.
It gives you a steady way to bring a digital tool into your maintenance operation without the usual headaches, if followed step by step.
Above all, start slow and begin with your own needs and a close look at your current processes before you pick tools.
Do that, and you give your new system the best possible chance to be adopted and improve how your team works.
6 Reasons for Digitizing Your Work Order Management
Key Takeaways:
Manual work order management produces more errors and decreases asset lifespan.
Digital work orders enable teams to work from a shared real-time view of the operation.
The world’s 500 largest companies lose $1.4 trillion a year due to unplanned downtime.
Imagine the following:
The technician who worked on the machine last week wrote the repair notes on paper, but no one can find the form.
A preventive maintenance inspection that should have happened three days ago was missed because the reminder was on a whiteboard in another building.
Someone forgot to order that critical spare part. Again.
For facilities managing maintenance through disconnected manual processes, these scenarios are all too common.
Luckily, digital work order (WO) management eliminates such inefficiencies through a centralized, real-time system for managing maintenance work, tracking assets, and keeping teams aligned.
In this article, we’ll explore six key reasons why digitizing your work order management can improve reliability, reduce downtime, and create a more efficient maintenance operation.
Improved Data Reliability
When maintenance records are managed through paper forms, sticky notes, or disorganized spreadsheets, errors accumulate quickly.
For instance, a technician might abbreviate an asset name differently each time, or fill in a work order from memory, hours after the job is done, forgetting key information.
Over time, these small inconsistencies erode the reliability of your maintenance data until the records your team depends on can no longer be trusted.
The operational consequences of such untrustworthy data can be severe.
Just ask Joyce Blom, a senior electrical reliability engineer at a major gas production facility:
“We had a case where a 15kV switch for a critical load was not in the […] system and was missed for its five-year maintenance. The switch eventually failed with an arcing short, causing a plant-wide power outage […]. The associated costs were significant.”
This shows that even a single missing or inaccurate maintenance record can lead to costly downtime, repair delays, and major operational disruptions.
Instead of each technician documenting work differently, your team uses a predefined format with consistent fields for asset names, failure types, priority levels, assigned technicians, labor hours, and parts used.
This consistency makes records easier to complete, review, search, and analyze.
Digital WO systems also improve data completeness by requiring specific fields.
Technicians cannot close or submit a work order until key information, such as time spent, replaced parts, or resolution notes, has been entered.
What once fell through the cracks is now captured automatically as part of the workflow.
Digitization also enables real-time syncing, keeping teams aligned as work progresses and reducing the risk of outdated or forgotten information.
A technician can update a work order status, log completed work, take photographs, and add inspection notes or signatures, all on the go.
David Berger, P.Eng., Partner at Western Management Consultants, a Canadian management consulting firm, explains why real-time data is so important in upkeep:
Ultimately, digital work orders significantly increase data consistency and visibility, reducing duplicate records, incomplete documentation, and conflicting information between teams.
This creates a maintenance data foundation your organization can actually trust when making operational, financial, and reliability decisions.
Real-Time Data Access
Better data is only half the equation.
The other half is being able to get to it instantly, from wherever you are.
With paper-based or spreadsheet-driven systems, information moves slowly.
A technician completes a repair, fills out a form, hands it to a supervisor, who eventually uploads it to a shared drive.
By the time that data is available to the rest of the team, hours or even days have passed.
Not only are decisions made during this gap based on incomplete or outdated data, but teams also waste significant time searching for it.
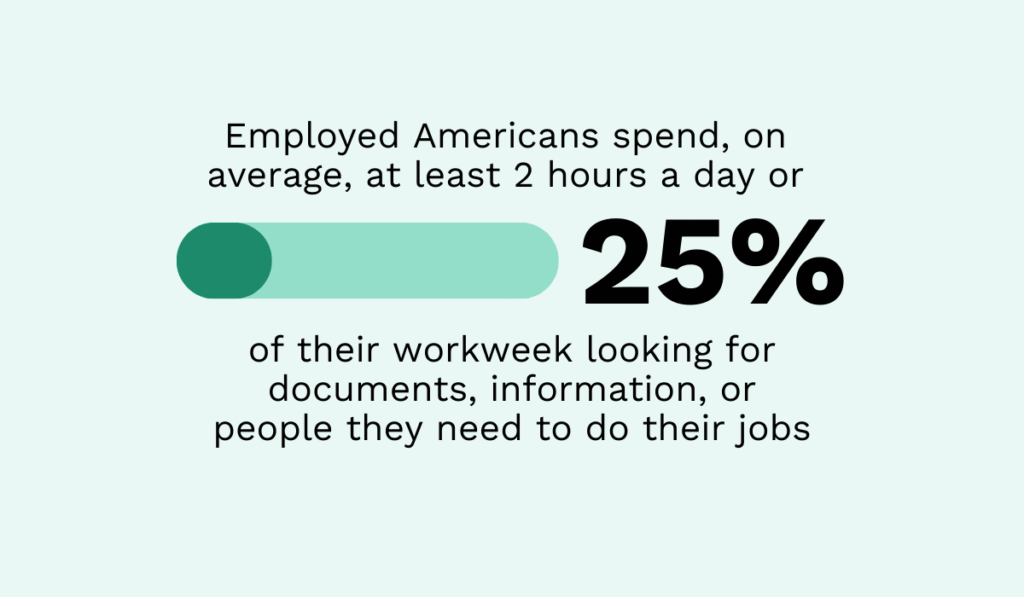
For instance, a Glean survey shows that American workers spend an average of two hours a day, or 25% of their workweek, searching for documents, information, or colleagues needed to complete tasks.
Fortunately, digital WO management eliminates these delays.
Since digital WO systems are often mobile-friendly, teams can access assignments, review job details, update work orders, and report issues from virtually anywhere, including directly from the shop floor.
As a result, everyone works from the same live information.
Supervisors can quickly verify job progress, planners can adjust schedules based on current equipment conditions, and technicians can respond faster when priorities change.
There are no manual handoffs, delayed updates, or disconnected spreadsheets slowing the flow of information.
Instead of tracking updates via calls, emails, or radio communications, the system provides a real-time view of maintenance activity across the facility.
This, ultimately, improves troubleshooting and repair quality.
When equipment fails, technicians can immediately pull up previous work orders, recurring issues, completed repairs, and parts history directly from a phone or tablet.
That context leads to:
Faster diagnostics
More informed repair decisions
Reduced downtime
In short, digital work orders enable your team to work from a shared real-time view of the operation.
This, in turn, leads to faster response times, better coordination, fewer communication gaps, and a maintenance process that can keep pace with the demands of the facility.
Increased Accountability
When maintenance work is managed manually, accountability often depends on trust.
You trust the technician completes the form, the supervisor approves the right work order, and the paperwork ends up where it’s supposed to.
When something goes wrong, like a missed inspection, a repeat failure, or a compliance gap, you’re left trying to reconstruct what happened from memory and incomplete records.
Digital WO management changes this by making every maintenance activity traceable.
Every action taken within the system is automatically tied to a person, a timestamp, and an asset.
Not because someone is constantly monitoring employees, but because traceability is built directly into the workflow.
Each work order automatically records key activity data, including:
Who created the work order
Which technician was assigned
When work started and ended
Status updates and approvals
Notes, comments, and uploaded photos
Parts used and labor hours logged
Asset repair and maintenance history
This way, digital work orders create clear ownership.
Instead of sitting in a general queue waiting for someone to claim them, work orders are assigned directly to specific technicians.
From creation to completion, the system tracks who received the task, when action was taken, and how long the work lasted.
As technicians update statuses, upload photos, log parts used, or document findings, the system automatically records those actions in real time.
This creates a complete maintenance history for every asset and repair activity.
If equipment fails shortly after a task was marked complete, you can review exactly what work was performed, what observations were documented, and who completed the repair.
One of the most practical accountability features in a digital WO system is mobile photo documentation.
Technicians can attach photos showing the equipment’s condition before and after repairs, document defects discovered during inspections, or capture meter readings directly in the field.
Those images become part of the permanent asset record, providing far more context than handwritten notes.
The result is a more transparent, consistent, and accountable maintenance operation in which work quality is easier to verify, compliance is easier to demonstrate, and critical knowledge is easier to share.
More Efficient Work Planning
Planning maintenance can be challenging without a proper system.
Someone has to:
remember which preventive maintenance tasks are coming up
decide which jobs take priority
identify the right technician for the task
verify parts availability
coordinate all of it across the facility
When that coordination is carried out through phone calls, printed lists, and whiteboard schedules, things inevitably fall through the cracks.
Tasks get missed, priorities are driven by urgency instead of business impact, and technicians arrive at jobs without the parts, tools, or information they need.
Digital work orders, on the other hand, lead to a more structured planning process, continuously keeping maintenance work organized, prioritized, and moving forward.
For instance, digital systems enable you to set a priority level for each task.
After all, not every work request carries the same level of operational risk.
A failure of a production-critical asset requires a different response than a flickering light in a storage room.
Digital WO systems allow you to define and enforce priority levels such as critical, high, medium, and low, ensuring technicians focus on the work with the greatest operational impact first.
When planners can review previous repairs, recurring failures, labor history, and asset condition trends, they can make better decisions about scheduling, staffing, and repair preparation.
They know which assets require specialists, which repairs typically take longer than expected, and which equipment may be approaching the end of its reliable service life.
All in all, the operational value of the structure and visibility introduced by digital work order management is significant.
Properly planned maintenance work consistently takes less time, causes fewer interruptions, and produces more reliable outcomes than reactive repairs.
When technicians arrive prepared, with the right parts, documentation, and context already available, work is completed faster, more safely, and with fewer repeat failures.
Stronger Preventive Maintenance Program
Better maintenance planning often leads to more effective preventive maintenance, which results in various improvements across operations and assets.
For instance, research from the NIST found that manufacturers relying on reactive upkeep experienced 3.3 times more downtime and 16 times more defects compared to those using more preventive and predictive maintenance strategies.
They also reported significantly higher lost sales and inventory disruptions tied to maintenance-related issues.
In other words, adopting a more proactive approach to maintenance directly translates to increased efficiency, reliability, uptime, and even profitability.
However, managing preventive maintenance through spreadsheets, paper schedules, and calendar reminders is extremely difficult.
Tasks get delayed or forgotten, intervals drift, and preventive maintenance gradually turns back into reactive upkeep with extra administrative work layered on top.
Digital WO systems are what make a PM program sustainable at scale. Take our own CMMS, WorkTrek, for instance.
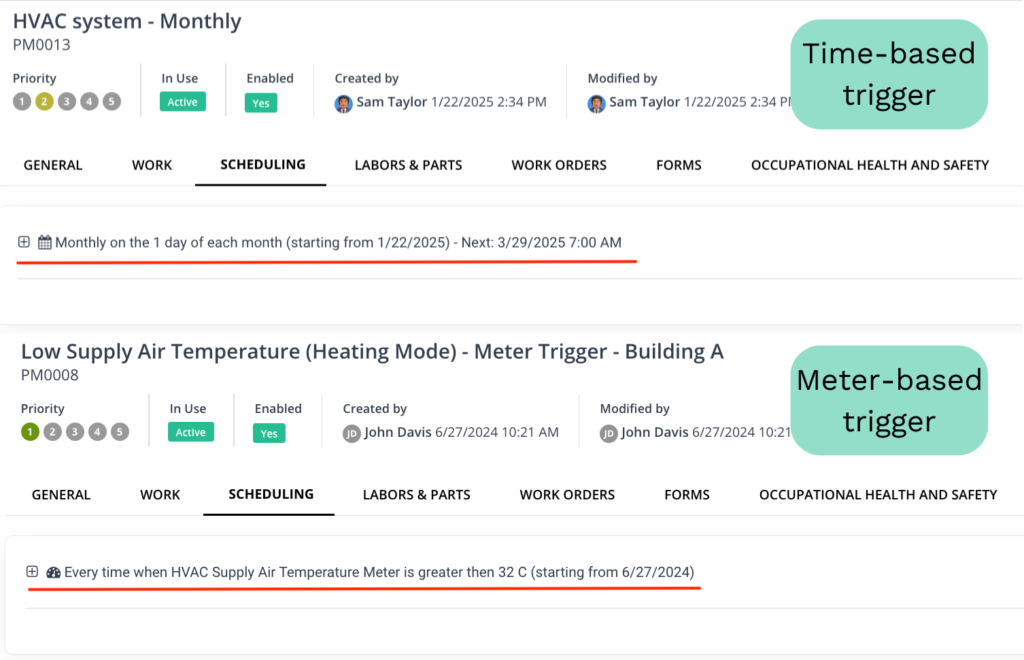
WorkTrek supports both time-based and meter-based PM scheduling, giving organizations the flexibility to align maintenance intervals with actual equipment usage.
You simply fill out the work order template, complete with SOPs, photos, checklists, and more, define the trigger, and the system takes care of the rest.
The assigned technician automatically receives a notification when the task is due and can instantly access the relevant work order from their phone.
If an inspection uncovers an issue, follow-up corrective work orders can be generated automatically.
The result is a better-planned preventive maintenance schedule that your team consistently follows, executing every task with the right procedures, parts, and safety measures in place.
No more missed tasks, constant firefighting, incomplete work orders, or running out of critical spare parts.
With WorkTrek, your preventive maintenance program finally works the way it should.
Reduced Costs
All the benefits we’ve covered so far ultimately impact your bottom line.
Better reliability, real-time visibility, stronger accountability, more efficient planning, and a stronger PM program reduce wasted time, minimize downtime, improve labor efficiency, and extend asset life.
Ultimately, the financial impact becomes visible across nearly every part of the operation.
Reduced unplanned downtime is often where most money is saved.
According to the 2024 Siemens report, the world’s 500 largest companies lose nearly $1.4 trillion annually due to unplanned downtime, approximately 11% of annual revenue.
Remember, when a machine fails unexpectedly, you’re not just paying the cost of lost production during the downtime.
You’re also paying a premium for the repair itself.
Emergency contractor rates, expedited parts shipping, and after-hours overtime are all expenses that disappear, or shrink dramatically, when maintenance is managed proactively through a digital system.
Digital WO management directly reduces these losses by enabling the preventive maintenance activities that keep equipment operating reliably.
Inventory management is another major area where digital maintenance systems reduce maintenance costs.
Without a digital system connecting parts usage to work orders and asset history, storerooms often accumulate excess inventory “just in case” while simultaneously running short on critical components actually needed for repairs.
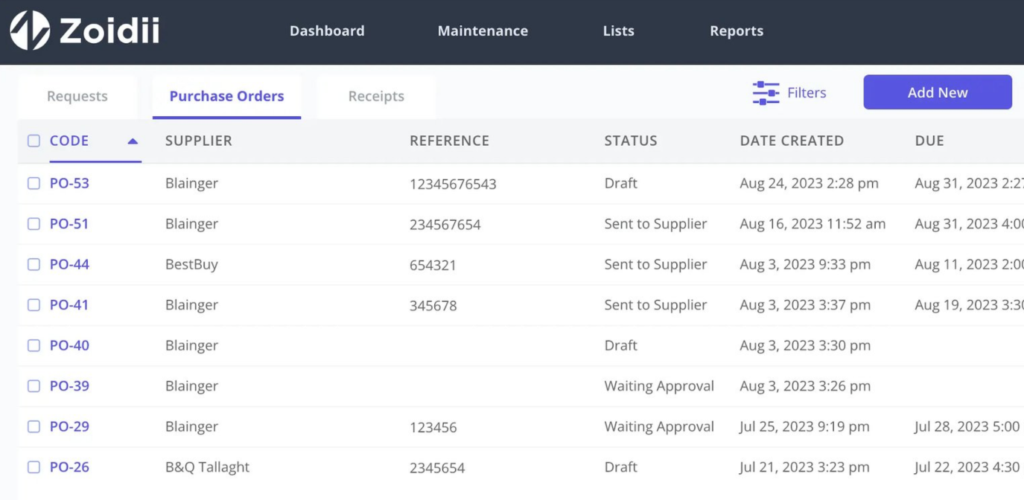
Digital WO systems, like the one shown below, improve inventory visibility by tracking parts consumption, recurring failures, and maintenance trends over time.
That’s right, digitizing work orders isn’t only about centralizing information or making technicians’ jobs easier.
It can also result in major cost savings for the entire organization.
Conclusion
Maintenance teams today are expected to reduce downtime while working with fewer resources, tighter budgets, and higher production demands.
Managing maintenance through paper forms, spreadsheets, and disconnected processes makes it increasingly difficult to meet those expectations.
Digitizing work order management is the only way forward.
It provides your team with accurate maintenance data, real-time visibility into ongoing work, stronger accountability, and more efficient planning and scheduling.
More importantly, it transforms maintenance from a reactive cost center into a structured, data-driven operation that improves reliability, supports production goals, and reduces long-term operating costs.
Best Maintenance Tracking Software Tools on the Market
Maintenance tracking software has evolved far beyond basic work order logging.
Today’s platforms help teams manage preventive maintenance, track asset history, monitor inventory, standardize inspections, and improve visibility across entire facilities from both desktop and mobile devices.
However, not every tool approaches maintenance tracking the same way.
Some focus on simplicity and fast implementation, while others lean heavily into predictive maintenance, production monitoring, or advanced asset intelligence.
In this guide, we review six maintenance-tracking software tools that stand out for their distinct strengths, beginning with our very own WorkTrek CMMS.
WorkTrek
No more relying on scattered and disorganized spreadsheets, paper checklists, or maintenance records. WorkTrek is built to bring everything into one place.
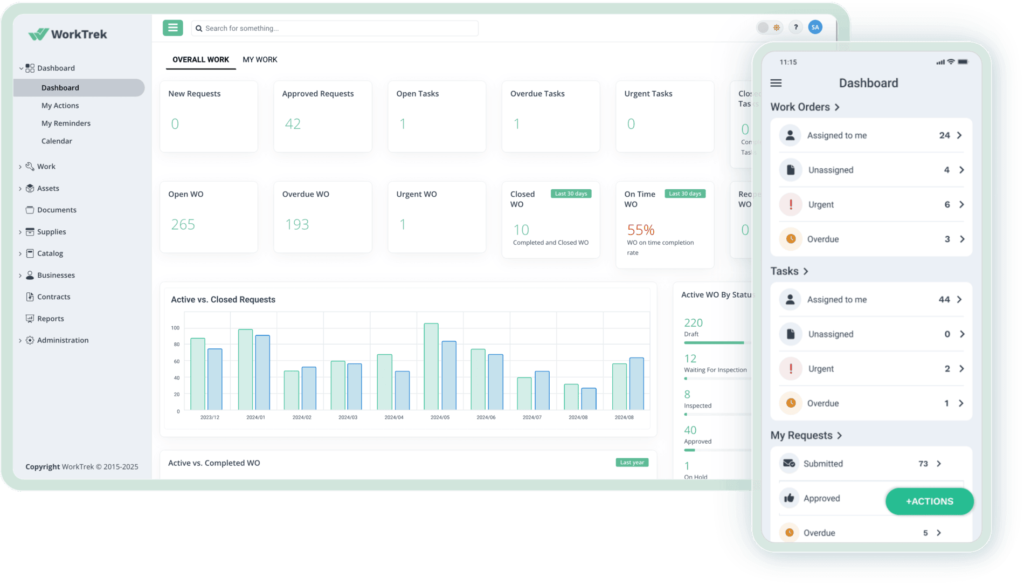
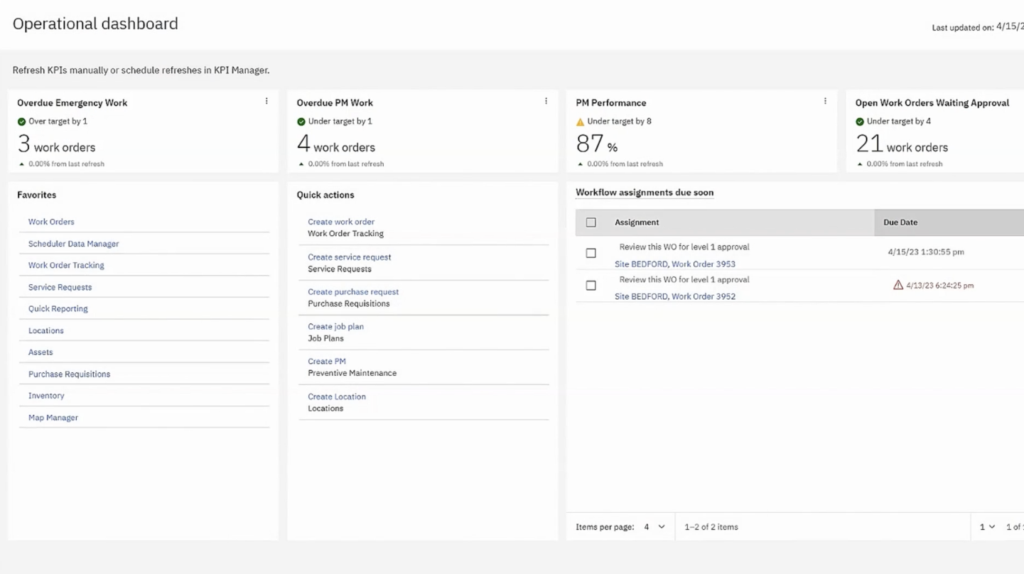
WorkTrek CMMS combines maintenance tracking, work orders, preventive maintenance, asset history, inventory, and maintenance requests inside a centralized system.
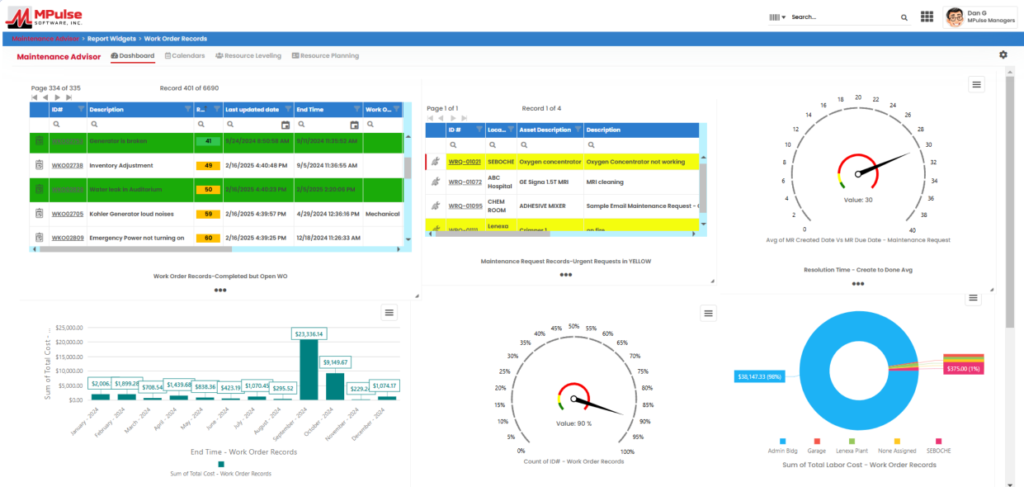
Below is WorkTrek’s dashboard, where you can find all of the above and easily track maintenance tasks.
Every completed task, inspection, checklist, uploaded image, and technician update stays attached to the asset record, making it much easier to track recurring issues, audits, and long-term upkeep performance.
You can also monitor who worked on what, when tasks were completed, and how long jobs took.
Teams can schedule recurring tasks (e.g., daily, monthly, yearly), attach digital procedures and inspections to each task, and thus standardize maintenance workflows across facilities or shifts.
Maintenance requests can be submitted through a portal, email, the WorkTrek mobile app, or even a branded request app, making it easier for operators and employees to report issues quickly.
Teams managing service contracts can monitor response and resolution times in real time to see whether maintenance work meets internal or customer service targets.
Technicians can create and update work orders, upload photos, scan barcodes, complete inspections, and access maintenance information directly from the mobile app.
The app also works offline, which is especially useful in plants, warehouses, or remote facilities with inconsistent connectivity.
Compared to platforms like Fabrico or Tractian, WorkTrek focuses less on production monitoring and predictive maintenance and more on giving teams a practical, centralized system for daily operations and long-term maintenance tracking.
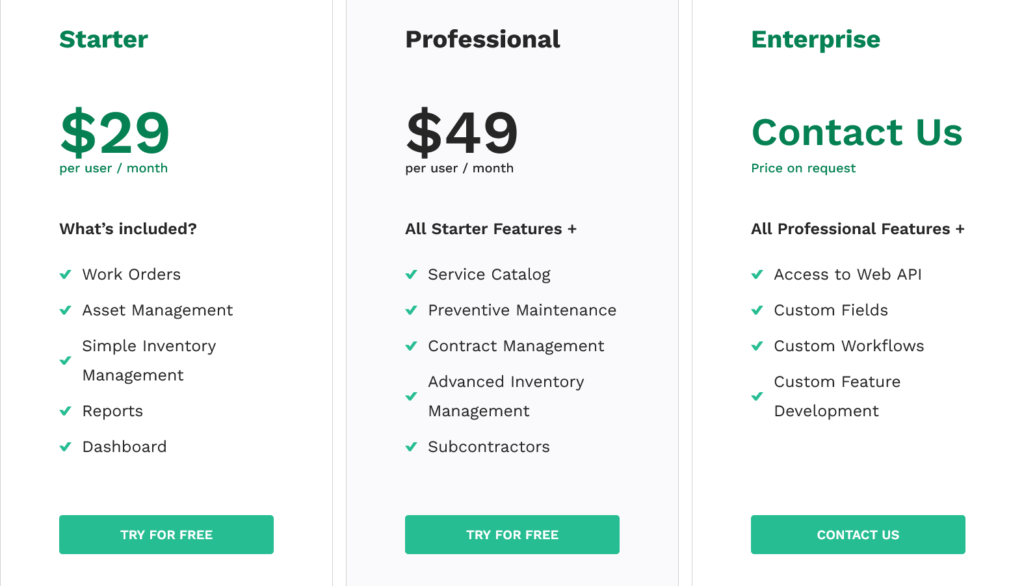
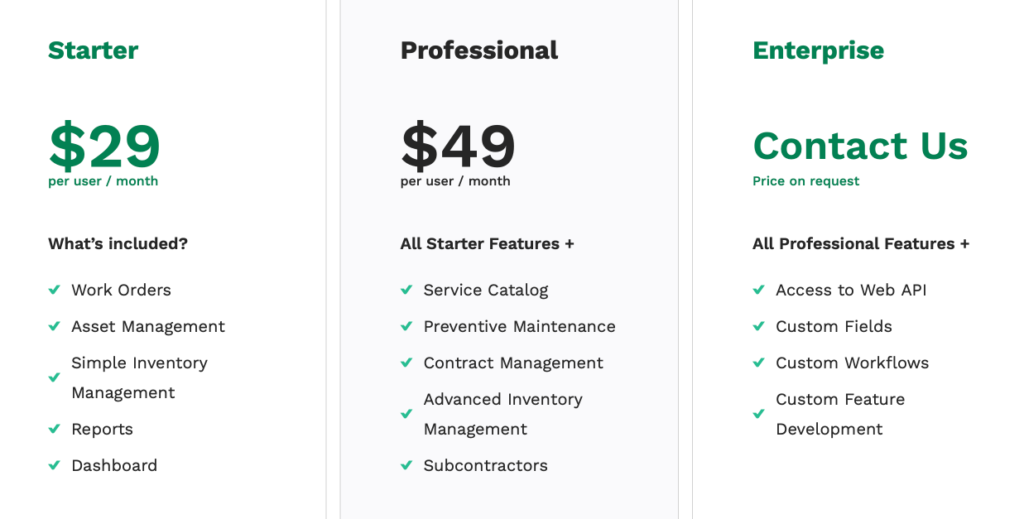
Pricing starts at $29 per user/month, and unlike some competitors on this list, WorkTrek supports unlimited assets across all pricing tiers.
That matters more than many companies initially realize, since asset or task limits can become restrictive as maintenance operations scale.
To sum up, WorkTrek is best suited for teams that want a modern, mobile-friendly maintenance-tracking platform with strong asset visibility features, without the complexity of larger, enterprise-heavy systems.
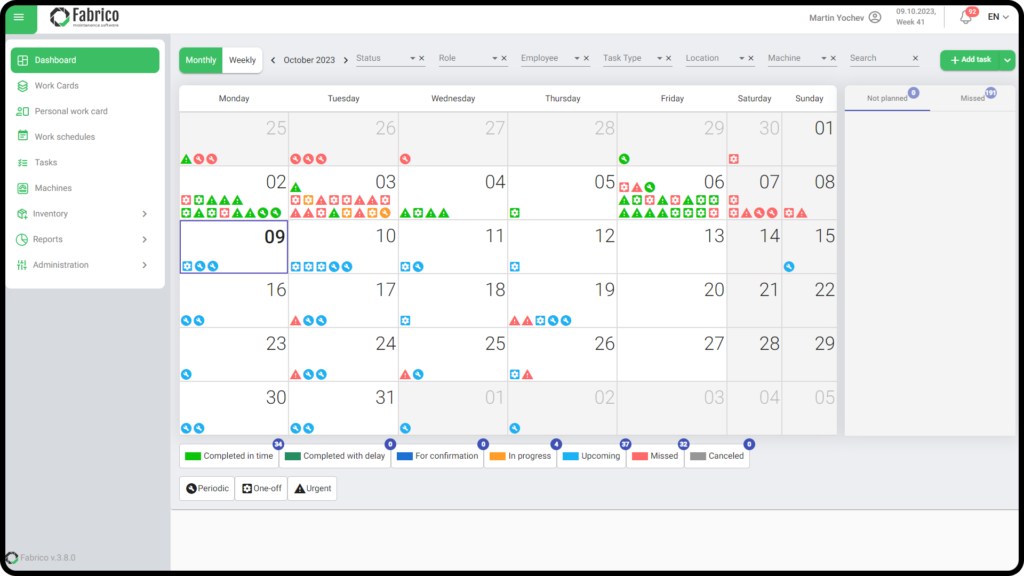
Fabrico combines CMMS functionality with production monitoring, which makes it feel quite different from more traditional maintenance tracking platforms.
Like WorkTrek, the platform covers the core maintenance tracking features most teams expect:
Preventive maintenance
Inventory management
Mobile functionality
QR-code scanning
Work orders
Reporting
You can manage assets in one place, create urgent maintenance tasks directly from the plant floor, and quickly pull up machine history or checklists by scanning a QR code.
Fabrico also puts a strong focus on shop-floor visibility.
Technicians can scan physical machines to instantly access digital lubrication procedures, cleaning checklists, maintenance history, and inspection records on a mobile device.
Where Fabrico really stands out is the connection between maintenance and production data.
The platform can connect directly to machine controllers or legacy equipment through gateway devices.
When a machine reaches a certain cycle count or fault condition, Fabrico can automatically generate a usage-based work order instead of relying on someone to manually report the issue.
The platform even includes computer vision functionality for manual assembly stations.
Overhead cameras can detect inefficiencies and capture downtime footage, while Fabrico’s Inefficiencies Zoom-In module connects OEE data with real production-floor video for visual root cause analysis.
Compared to WorkTrek or Maintainly, Fabrico leans much more heavily into manufacturing intelligence and operational analytics rather than just maintenance workflows.
That said, it’s important to note that some of Fabrico’s AI-focused capabilities are still add-ons or beta features rather than part of the standard platform.
Features such as AI-driven schedule optimization and generative troubleshooting assistance are currently on the company’s roadmap.
Some users also mention that the platform can feel slightly overwhelming at first.
On G2, reviewers noted that the dashboard may feel too data-heavy for teams unfamiliar with analytics-focused systems, while others mentioned that the scheduling interface could be more intuitive.
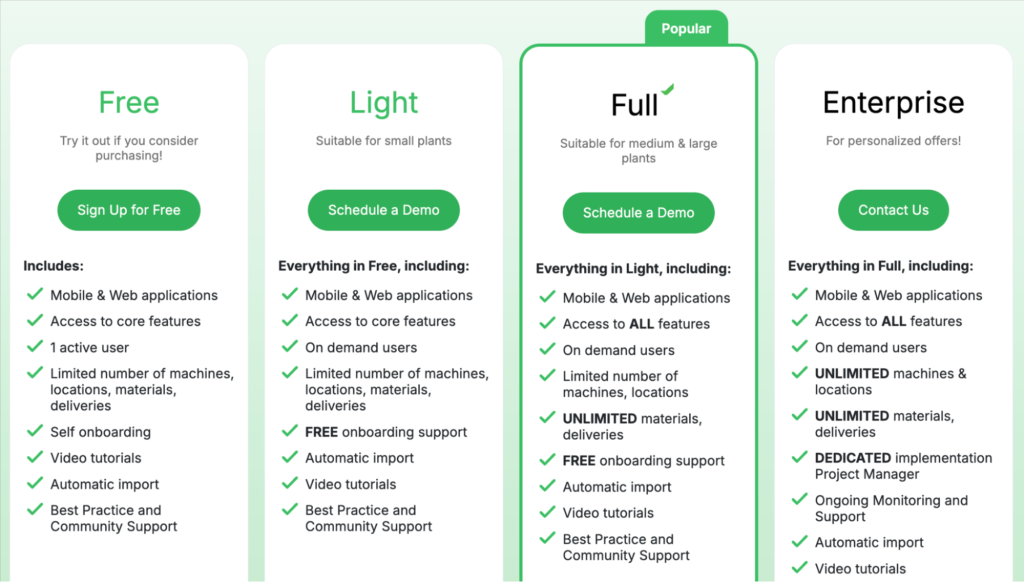
More importantly, lower plans come with asset and operational limits.
For example, the Free plan only supports up to 10 machines, 10 locations, and 200 tasks, while unlimited machine tracking is reserved for the Enterprise plan.
Reporting and analytics are only available in the more advanced plans, while work scheduling functionality is restricted to the Enterprise tier.
Overall, Fabrico feels best suited for larger manufacturing companies that want maintenance tracking tightly connected to production performance, machine data, and operational visibility.
Makula
Makula is a maintenance tracking platform that puts a strong focus on asset structure, inspections, and technician workflows.
The platform includes the core CMMS features, such as:
Work order management
Preventive maintenance
Inventory tracking
Inspections
Mobile functionality
Analytics
Compared to some simpler maintenance tracking tools, Makula stands out most in the way it organizes assets.
You can create parent and child assets, build clear equipment hierarchies, and link spare parts directly to specific machines or components.
That makes it much easier for technicians to understand how assets are connected and what parts are needed before starting work.
Preventive maintenance workflows are also flexible.
Teams can schedule multiple recurring tasks for the same asset (monthly, annually, biannually, or custom intervals) while attaching procedures, inspections, and digital checklists directly to the work order, similar to WorkTrek.
Makula also does a good job with inspection tracking.
Technicians can complete checklists directly from the app, upload photos, collect signatures, and keep a detailed history of completed inspections, observations, and maintenance activity tied to each asset.
Similar to Fabrico, though, these AI features are modular rather than built into the standard platform.
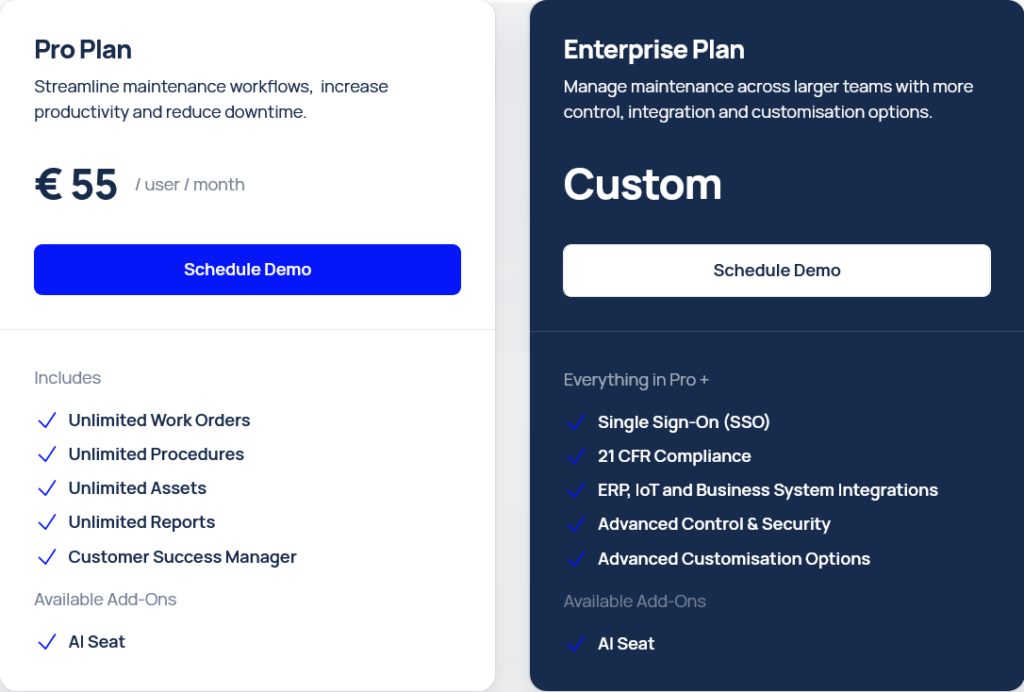
Pricing starts at €55 per user/month for the Pro plan, with unlimited assets included.
However, some advanced functionality, including ERP integrations, API access, advanced security controls, and IoT integrations, is reserved for custom enterprise plans or comes with additional implementation costs.
That implementation complexity is something buyers should keep in mind.
According to Research.com, ERP integrations and API setup may require additional consulting hours, which can increase both implementation time and overall cost.
Some users also report that the mobile experience is currently stronger on Android than iOS.
Overall, Makula feels best suited for teams that need strong asset hierarchy management, detailed inspection tracking, and flexible preventive maintenance workflows without moving fully into enterprise-level complexity.
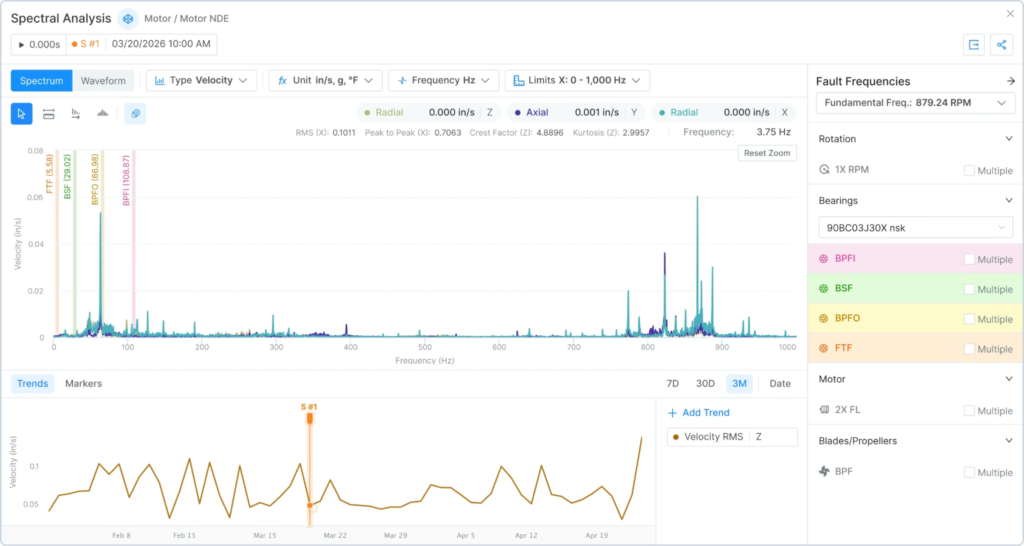
Tractian
Instead of focusing mainly on work orders and preventive maintenance, Traction combines three connected systems: CMMS, condition monitoring, and OEE tracking.
That makes it feel closer to an industrial reliability platform than a traditional CMMS.
On the maintenance side, Tractian includes the core features most teams expect:
Work order management
Preventive maintenance
Parts inventory
Mobile app
Checklists
SOPs
Through the app, technicians can monitor asset status, access upkeep history, manage work orders, and navigate asset trees that show how equipment and components are connected across the facility.
Instead of waiting for operators or technicians to notice issues manually, the system can automatically trigger alerts when abnormal machine behavior is detected.
Teams can also automate recurring maintenance tasks by connecting them directly to machine health insights and sensor data, helping shift maintenance operations from reactive to predictive maintenance.
For manufacturing companies, Tractian also adds OEE and production analytics into the same ecosystem.
Teams can monitor production lines, operator performance, downtime trends, and process analytics through live dashboards and AI-powered reporting tools.
Compared to platforms like WorkTrek or Maintainly, Tractian is much more focused on predictive maintenance and industrial monitoring than day-to-day maintenance administration.
That hardware-first approach does come with tradeoffs, though.
In Reddit discussions, some users mentioned that Tractian’s hardware-as-a-service model can become expensive compared to building monitoring systems with third-party sensors.
Others noted that the platform appears heavily optimized for manufacturing environments and may feel less flexible for mixed operations or facilities maintenance teams.
One Reddit user also pointed out concerns around scalability and integrations, mentioning that some advanced functionality relies heavily on Tractian’s own hardware ecosystem.
Pricing starts at $60 per user/month for the Standard plan, with a five-user minimum.
Both Standard and Enterprise plans include unlimited assets and unlimited requesters, while the Bundle plan combines the CMMS platform with Tractian’s condition-monitoring sensors and predictive maintenance tools.
All things considered, Tractian is best suited for industrial and manufacturing companies that want maintenance tracking tightly integrated with machine health monitoring, reliability analysis, and predictive maintenance workflows.
eMaint
eMaint combines CMMS, EAM, and IIoT functionality inside a cloud-based system from Fluke Reliability.
Core features include:
Mobile maintenance tools
Preventive maintenance
Spare parts inventory
Condition monitoring
Asset management
Work orders
Reporting
One area where eMaint stands out is preventive maintenance flexibility.
Teams can create calendar-based PMs, meter-based PMs, or combine multiple triggers for the same asset.
For example, maintenance can automatically trigger based on runtime hours, mileage, production output, or custom thresholds.
The platform also handles complex asset structures well.
Similar to Makula, eMaint supports parent-child asset relationships, allowing teams to manage multiple connected assets inside the same maintenance workflow.
That becomes especially useful for production lines, fleets, or larger facilities where maintenance tracking can quickly become difficult to manage manually.
Another strong point is mobile maintenance tracking.
Technicians can scan QR codes or barcodes to pull up asset details, maintenance history, spare parts, and open work orders directly from the field.
The mobile app also supports offline work, allowing technicians to complete tasks and sync updates once connectivity returns.
That makes eMaint more comparable to platforms like WorkTrek and Makula in terms of field usability.
Compared to Tractian or Fabrico, though, eMaint focuses less on production monitoring and predictive maintenance, and more on configurable maintenance workflows and enterprise asset management.
That flexibility is one of the reasons users on Reddit and G2 often praise the platform.
Many companies note that eMaint adapts well across industries and maintenance operations, rather than being tied heavily to manufacturing alone.
At the same time, several users note that the system can occasionally feel overly detailed or repetitive, especially during setup and workflow configuration.
Pricing starts at $69 per user/month with a three-user minimum, and all plans support unlimited assets.
However, some important maintenance-tracking features, including mobile offline work, QR-code request functionality, and unlimited request logins, are reserved for higher-tier plans.
Altogether, eMaint feels best suited for organizations that need highly configurable maintenance tracking, detailed preventive maintenance workflows, and scalable asset management across larger or more complex operations.
Maintainly
Compared to some of the larger CMMS platforms on this list, Maintainly takes a much simpler and more lightweight approach to maintenance tracking.
The platform focuses on the core features maintenance teams use daily:
Mobile maintenance workflows
Preventive maintenance
Maintenance requests
Asset tracking
Work orders
Audit history
Instead of trying to turn the system into a large enterprise platform, Maintainly keeps things relatively easy to implement and navigate.
That simplicity is actually one of its biggest selling points, and that’s why this tool is also suited for hotels, churches, aged care, and sports facilities.
Teams can create preventive or reactive maintenance tasks, scan QR codes to pull up assets and work orders, upload photos and files, and manage maintenance requests directly from the mobile app.
Service reports, uploaded documents, technician notes, completed work orders, downtime records, and parts usage all stay attached to the asset history, making it easier to troubleshoot recurring issues or track maintenance activity over time.
Unlike platforms like Tractian or Fabrico, Maintainly is not focused on predictive maintenance or production analytics.
Instead, it focuses on making maintenance tracking accessible, mobile-friendly, and easy to roll out quickly.
The company even highlights that only 2% of customers require formal training to start using the platform.
Pricing is one of Maintainly’s strongest advantages.
The platform offers a free plan with unlimited work orders, mobile access, repeating tasks, checklists, meter readings, QR asset labels, and unlimited request users.
Paid plans start at €8 per user/month, while more advanced reporting, API access, and unlimited preventive maintenance are reserved for the Enterprise tier.
However, keep in mind that inventory management and timesheet tracking are available only as optional add-ons.
Overall, Maintainly feels best suited for small- to mid-sized maintenance teams that want a clean, mobile-friendly maintenance-tracking system without the implementation complexity or pricing structure of larger enterprise CMMS platforms.
Conclusion
Maintenance tracking software can help you define how clearly you see your assets, how fast you react to issues, and how effectively you prevent downtime.
Some tools we covered today focus on simplicity and fast adoption, others on deep analytics, predictive maintenance, or full production visibility.
As always, the right choice comes down to what your operation actually needs today, and how much complexity you’re ready to scale into tomorrow.
6 Steps to Overcoming Common Maintenance Issues
Key Takeaways:
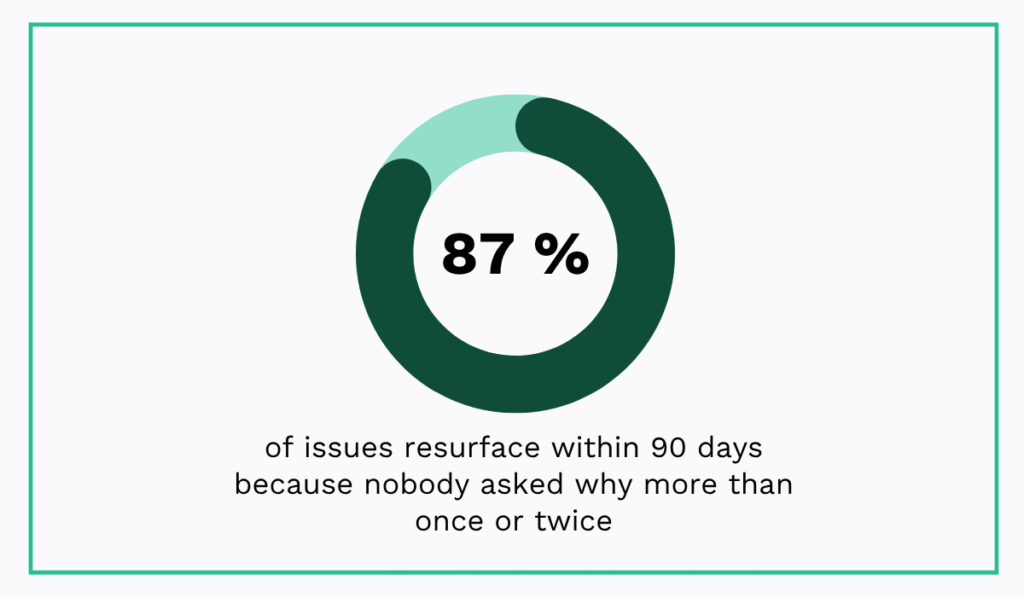
87% of maintenance issues resurface within 90 days without root cause analysis.
Unplanned downtime costs many facilities at least $10,000 per hour.
Proper documentation prevents knowledge loss and repeated mistakes.
Unexpected downtime, recurring equipment failures, missing parts, poor documentation, and constant firefighting are some of the most common maintenance problems teams face today.
In most cases, these issues build over time through reactive processes, inconsistent maintenance, and a lack of visibility.
Fortunately, they are all fixable.
Here are six practical steps upkeep teams can take to reduce downtime, improve reliability, and stay ahead of maintenance problems.
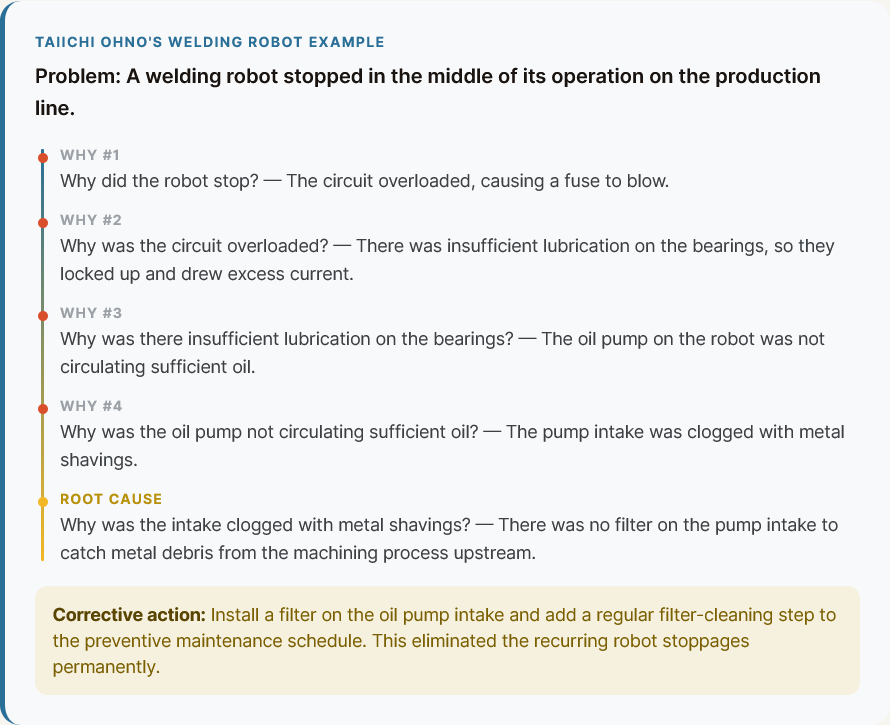
Identify the Root Cause of the Issue
One of the biggest maintenance mistakes is fixing the immediate problem without determining why it happened in the first place.
That’s how teams end up repairing the same asset over and over again.
Over time, recurring problems lead to increased downtime, higher repair costs, and growing frustration across operations.
In the end, the real issue wasn’t the fuse, but contamination and missing filtration procedures.
If you still aren’t sure whether RCA is worth the effort, consider this: research shows that 87% of issues recur within 90 days when teams fix surface-level symptoms rather than the underlying cause.
Therefore, when equipment fails, don’t stop at the broken part.
Review repeat work orders, involve the technicians who handled the repair, and ask enough questions to uncover what allowed the issue to happen in the first place.
Standardize Preventive Maintenance
A lot of maintenance problems become emergencies simply because small issues were not caught early enough.
Inspections get overlooked, lubrication gets delayed, minor faults go undocumented, and eventually, something fails unexpectedly.
Unfortunately, that reactive cycle is expensive.
According to a global report by ABB, 83% of facilities estimate that unplanned downtime costs at least $10,000 per hour, while 76% put the figure as high as $500,000 per hour.
The good news is that many of these failures are preventable, but only if preventive maintenance is conducted consistently.
That’s where many teams struggle.
They may already have preventive maintenance schedules in place, but the process itself is often inconsistent.
Tasks live in spreadsheets, work orders get lost, technicians rely too heavily on memory or verbal communication, and in the end, many teams still spend more time reacting to failures than preventing them.
Yes, you read that correctly: less than 35% of facilities spend most of their time on planned tasks.
Here’s how to do things differently and ensure maintenance success.
First, clearly define:
What needs to be inspected
How often should maintenance happen
What should technicians check
How completed work should be documented
Prioritize high-impact recurring tasks such as lubrication, calibration, filter replacements, and safety inspections. These tasks often get overlooked in reactive environments.
Now, the easiest way to manage preventive maintenance consistently is with a CMMS like WorkTrek.
For example, instead of manually tracking preventive maintenance schedules in spreadsheets or on whiteboards, you can use recurring work orders to automatically schedule routine maintenance activities.
You can schedule PM based on time intervals or meter readings after specific usage time, mileage, temperature, pressure, and other factors.
Another great thing about using a CMMS is that everything is in one place.
Technicians can use centralized asset histories to quickly see previous repairs, recurring issues, completed inspections, and technician notes before starting work on an asset.
That speeds up troubleshooting and helps teams notice patterns that would otherwise get missed.
To ensure maintenance is performed consistently across the entire team, you can even attach digital checklists and standardized procedures to work orders.
This way, every technician can follow the same process every time, regardless of shift, location, or experience level.
Upgrade Documentation Management Processes
A lot of maintenance teams rely heavily on the one person who knows everything.
The problem is that once that person is unavailable, troubleshooting suddenly becomes much slower and more chaotic.
Technicians waste time searching for manuals, repeating old mistakes, or trying to remember how a repair was handled the last time equipment failed.
Apparently, this scenario is more common than one might think, in every industry.
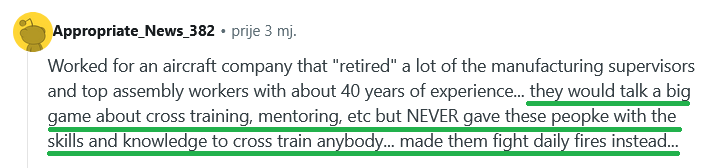
In a Reddit discussion about tribal knowledge in engineering teams, one engineer described how an aircraft manufacturer allowed several experienced supervisors to retire without first properly transferring their knowledge.
According to the post, the company later faced a huge vacuum and a ton of rework, eventually bringing some retirees back as consultants because critical assembly knowledge had been lost.
In other words, failing to document work properly costs money.
Beyond costs, poor maintenance documentation can also be dangerous.
In a recent investigation involving a fatal UPS cargo jet crash, the NTSB found that inconsistent communication and incomplete reporting created blind spots around recurring bearing damage issues.
Several previous incidents were either poorly documented or never fully reported, making it harder to recognize the scale of the problem before the accident happened.
That’s why maintenance teams should document knowledge before it disappears.
Start by creating SOPs for recurring inspections, repairs, shutdown procedures, and troubleshooting processes.
Then make sure technicians can access them quickly when they need them.
A CMMS can help by giving teams one centralized place to store asset histories, maintenance notes, manuals, photos, and SOPs tied directly to each piece of equipment.
And most importantly, technicians should be able to access all this information in the field through their mobile phones.
Keep Spare Parts Ready
Even the best maintenance teams can’t fix equipment if the necessary parts are unavailable.
Unfortunately, many organizations only realize a spare part is missing after a critical asset is already down.
That situation can escalate quickly.
Maintenance engineer Jan Barraclough described watching cyclone feed pumps repeatedly fail during a single shift as worn vee-belts disintegrated one after another.
But the real problem appeared afterward.
The site had no spare pulleys available and nothing already on order.
Without replacement parts on site, the team was forced into emergency shipments and months-long lead times, as Barraclough explained:
“Due to the cost of ‘hot-shotting’ them to site, I was only allowed to have 1 set of pulleys and taper locks flown in… the other pulleys and belts would have to come by road (6 months away).”
Once a critical component fails, teams often end up dealing with production losses, emergency shipments, temporary fixes, and months of operational risk just to keep equipment running.
To avoid situations like this, first identify your critical spare parts. These are the components that would immediately disrupt operations if they failed and were unavailable.
Then define minimum stock levels based on:
Asset criticality
Supplier lead times
Failure frequency
How long could operations realistically run without the part
With a CMMS, you can track spare parts inventory alongside maintenance activities, monitor which parts are running low, and link components directly to assets.
In the end, downtime often lasts much longer than the repair itself when teams are stuck waiting for parts to arrive.
Train Your Team Regularly
Maintenance problems are rarely caused by equipment alone.
In many cases, the bigger issue is whether technicians have the skills, knowledge, and confidence to maintain that equipment properly.
Even the best preventive maintenance plans, monitoring systems, and maintenance software will fail if teams do not know how to use them correctly.
And this challenge is growing.
Modern facilities rely on increasingly complex equipment, automated systems, and digital maintenance tools, while experienced technicians are retiring faster than companies can replace them.
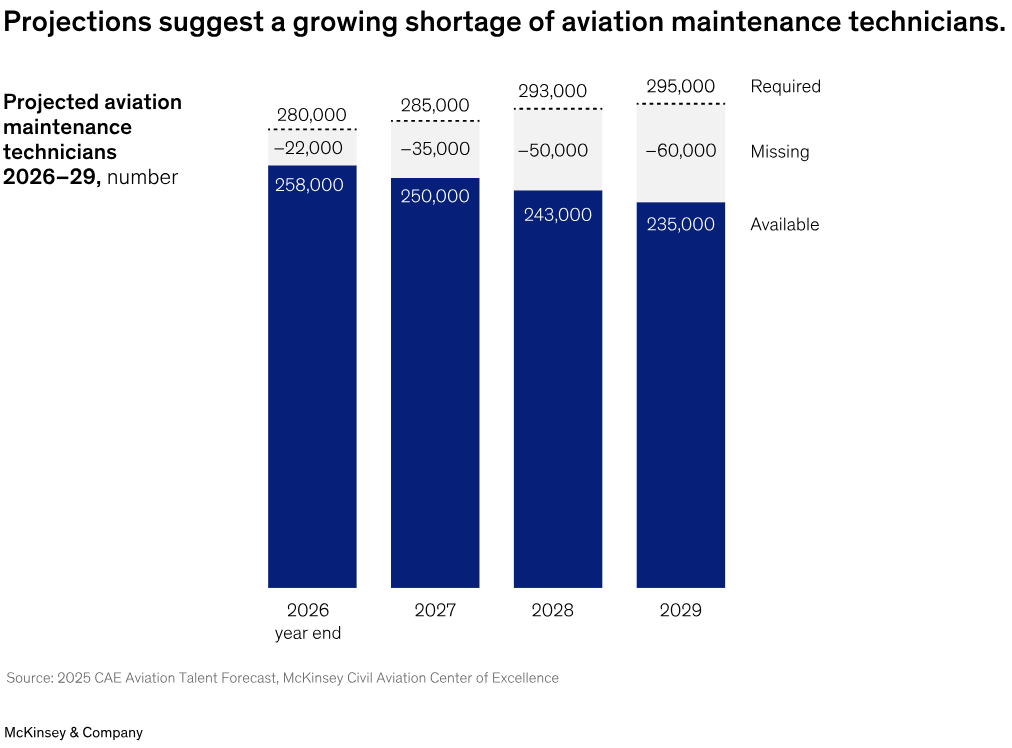
A McKinsey analysis of the aviation maintenance sector, for example, found that the industry could face a shortage of roughly 60,000 technicians by 2029.
In day-to-day maintenance operations, this problem usually shows up as missed warning signs, inconsistent inspections, incorrect repairs, repeat failures, and longer troubleshooting times.
If that sounds familiar, your maintenance training needs to become more practical and continuous, and not something that only happens during onboarding.
Instead of relying heavily on classroom-style instruction, focus on training that reflects real maintenance situations. For example, you can:
Troubleshoot real breakdown scenarios
Practice inspections on actual equipment
Simulate common failures your team regularly encounters
Walk through “what would you do if this happens?” exercises
This type of hands-on learning helps technicians build confidence in real operating conditions, not just understand procedures in theory.
Cross-training is equally important.
If only one technician knows how to troubleshoot a critical asset, your operation becomes vulnerable every time that person is absent, overloaded, or leaves the company.
Therefore, ensure knowledge is shared across the team. Have technicians shadow each other, rotate responsibilities occasionally, and document lessons learned after major repairs or failures.
You should also standardize how maintenance work is performed.
Clear checklists, visual instructions, and structured reporting processes help reduce mistakes, especially during busy shifts or high-pressure situations.
And with a CMMS, you can make those procedures easily accessible in the field, attach instructions directly to work orders, and ensure technicians follow the same maintenance process every time.
Ultimately, better training doesn’t equal running more courses.
In fact, it all comes down to ensuring your team can respond confidently, consistently, and correctly when real maintenance problems happen.
Keep Monitoring Your Operations Closely
Many maintenance teams operate reactively simply because they do not have enough visibility into what is happening across their operations.
Equipment performance slowly declines, small faults keep repeating, downtime becomes more frequent, and maintenance backlogs grow, but nobody notices the pattern early enough to act on it.
That’s why maintenance teams need to continuously monitor both equipment condition and maintenance performance, not just react after breakdowns occur.
And you do not need an overly complicated system to start doing this well.
In fact, one of the biggest mistakes teams make is trying to track too much data at once.
A much better approach is to start with just a few key indicators tied to your most critical assets.
For example, you can track:
Downtime frequency
Temperature or vibration changes
Recurring error rates
Maintenance backlog
Mean time to repair (MTTR)
A good CMMS can help you monitor these metrics automatically and visualize them through dashboards and reports.
That makes it much easier to identify recurring issues, declining asset performance, and patterns before they turn into major operational problems.
This kind of deeper monitoring becomes especially valuable for critical assets where even a small failure can cause significant downtime.
In those cases, teams often go beyond KPIs and use condition-monitoring tools such as vibration analysis, temperature sensors, and real-time equipment monitoring.
That’s exactly what Ingredion, a global food ingredient manufacturer, did after repeated equipment failures caused costly downtime at one of its plants.
In one case, a critical pump with no backup failed, causing a full three-day shutdown.
After implementing real-time condition monitoring, the company started detecting developing issues much earlier.
In one standout case, monitoring tools identified a looseness defect on another critical pump before failure occurred, allowing the maintenance team to create a work order immediately and avoid another major shutdown.
According to Ingredion, this approach helped one facility achieve:
$1 million in production savings
$223,000 in maintenance savings
Between 48 and 168 hours of avoided downtime across critical equipment
Because in maintenance, the earlier you notice a problem, the easier and less expensive it is to fix.
Conclusion
Maintenance can indeed be full of challenges.
But as you’ve seen throughout these steps, most common maintenance issues are preventable with the right processes and habits.
Even small improvements in preventive maintenance, documentation, training, inventory management, or operational monitoring can significantly reduce downtime and help you stay ahead of recurring problems.
Review these steps, identify where your biggest gaps are today, and start improving one process at a time.
Implementing Maintenance Software? Here are the Challenges Most Teams Run Into
Key Takeaways:
58% of software buyers regret at least one software purchase.
Workers lose about 2.33 hours every week due to software-related challenges.
Implementation challenges often have more to do with people than technology.
Clear goals, executive support, and training can improve software adoption rates.
Maintenance software can transform how a team plans work, tracks assets, and prevents downtime. Yet many implementations don’t go as smoothly as expected.
Maybe you’ve already seen some warning signs.
Technicians are hesitant to adopt a new system, leadership wants results but hasn’t clearly defined what success looks like, or perhaps you’re worried about investing in software only to discover it doesn’t solve the problems you hoped it would.
The good news is that most implementation challenges are predictable and preventable.
In this article, we’ll look at the most common obstacles maintenance teams face when implementing new software and what you can do to avoid them.
Unclear Goals
Companies often implement maintenance software before clearly defining what they’re trying to achieve.
The conversation often starts with a general desire to improve efficiency or modernize maintenance operations.
While those goals sound reasonable, they’re too vague to guide software selection, implementation decisions, or long-term success.
As a result, teams end up evaluating software features without first identifying the problems those features are supposed to solve.
Alex J. Johnson, founder of MaintenanceMatters Consulting and a maintenance systems consultant with more than a decade of implementation experience, has seen this happen repeatedly.
“I consulted for a midsize chemical processor (…). Their executives bought an industrial-grade CMMS with modules their maintenance team never asked for. Eight months and $130K later, they were still using Excel spreadsheets for work orders.”
The software wasn’t necessarily the problem.
The organization never established a clear connection between its maintenance challenges and the solution it purchased.
Johnson shared a very different example from a food processing facility that approached implementation with specific objectives in mind.
Before evaluating software, the team identified the issues they wanted to fix:
Nearly 30% of preventive maintenance tasks were being missed each month
Work orders took an average of 4.3 days to complete
Compliance documentation required roughly 11 hours of work every week
Inventory inaccuracies were causing multiple downtime events each month
Because the team knew exactly what needed improvement, selecting the right system and measuring whether it worked became much easier.
According to Johnson, the facility eventually reduced missed preventive maintenance tasks to less than 8% and cut average work order completion time to 1.7 days.
Research suggests this approach is common among successful technology initiatives.
According to WalkMe’s 2024 State of Digital Adoption report, 44% of organizations with successful digital adoption programs align technology initiatives directly with business outcomes.
Therefore, before evaluating maintenance software, take time to identify the metrics and processes that need improvement. Ask questions such as:
Are preventive maintenance tasks being missed?
Is downtime occurring more frequently than expected?
Are technicians spending too much time searching for information?
Is compliance documentation difficult to manage?
Do work requests regularly fall through the cracks?
The more specific your objectives are, the easier it becomes to choose software that addresses your needs instead of simply offering the longest feature list.
And perhaps more importantly, you’ll have a clear way to measure whether the implementation was successful once the software goes live.
Resistance to Change
Even the most capable maintenance software will fail if people don’t use it.
That sounds obvious, but many organizations underestimate how difficult it can be to change established maintenance routines.
Technicians who have spent years relying on paper records, spreadsheets, whiteboards, or legacy systems may view new software as an unnecessary complication rather than an improvement.
From their perspective, the current process works well enough. They know where information is stored, how work gets assigned, and what needs to be done each day.
Introducing a new system can feel like extra work, especially if they don’t immediately understand how it will make their jobs easier.
This is why software implementation is often more about people than technology.
After analyzing dozens of CMMS implementations, maintenance consultant Alex J. Johnson came to a simple conclusion:
One of his most successful clients, a large manufacturing facility that achieved an impressive 99% CMMS adoption rate, didn’t focus on selling employees a new software platform.
Instead, they focused on solving everyday frustrations. The maintenance supervisor in that facility explained:
“People don’t resist change. They resist pain. Show them how you’re removing pain, not adding it.”
That’s an important distinction.
If technicians believe the new system will create more administrative work, require endless data entry, or slow them down in the field, resistance is almost inevitable.
On the other hand, if they see that the software can help them find asset histories faster, access procedures on a mobile device, reduce paperwork, or simplify work order management, adoption becomes much easier.
Maintenance professionals themselves often point to usability and value as the deciding factors.
Others echoed a similar sentiment, noting that if software takes more time to use than it saves, many technicians will quickly abandon it.
So, don’t wait until implementation is complete to start talking about benefits.
Instead, involve maintenance teams early in the process.
Ask them about their biggest frustrations with current workflows. Show them how the new system will help solve those problems.
Demonstrate features that directly support their daily work rather than overwhelming them with every capability the software offers.
For example, instead of saying:
“The new software has advanced reporting and workflow automation features.”
Try explaining:
“You’ll be able to pull up an asset’s maintenance history in seconds instead of searching through folders or spreadsheets.”
The second message connects directly to a problem technicians experience every day.
When employees understand how the software helps them do their jobs more efficiently, they’re far more likely to embrace the change.
Lack of Executive Support
Many organizations treat maintenance software implementation as a maintenance department project, when in reality, it’s a business project.
While maintenance teams may use the software every day, its success depends heavily on leadership support.
Budget approvals, implementation timelines, training resources, and organizational priorities are all influenced by executive decisions.
When leadership is actively involved, teams are more likely to receive the resources and support they need.
However, when executive attention fades after the software purchase is approved, implementation often loses momentum.
Organizations with successful digital adoption strategies understand this.
According to WalkMe’s 2024 State of Digital Adoption report cited above, 68% of enterprises have six or more employees dedicated to managing digital adoption efforts.
The finding highlights an important reality: implementing new technology requires ongoing support, not just a software purchase.
Before implementation begins, secure an executive sponsor who understands both the project’s purpose and the expected outcomes.
Instead of focusing on software features, connect the investment to business goals such as:
reducing downtime
improving asset reliability
increasing preventive maintenance compliance
lowering maintenance costs
Just as importantly, keep leadership informed throughout the rollout. Sharing early wins and measurable improvements helps maintain engagement and reinforces the project’s value.
When executives visibly support the implementation, employees are far more likely to view it as a priority, and the chances of long-term adoption increase significantly.
Inadequate Training
A common assumption is that once maintenance software is installed, employees will naturally figure out how to use it.
However, in reality, even the most intuitive software requires training. Without it, users often become frustrated, avoid certain features, or revert to old processes altogether.
The problem isn’t usually a lack of willingness. More often than not, employees simply don’t feel prepared.
When asked why they felt unprepared to use new workplace technologies, nearly 34% said they weren’t given enough time to learn them before being expected to use them, while 18% felt the training they received wasn’t thorough enough.
These numbers reveal that successful software implementation requires more than a single onboarding session.
Maintenance consultant Alex J. Johnson saw this firsthand while working with a healthcare facility implementing a CMMS.
To support adoption, the team created short 10-minute video tutorials covering each core function employees needed to perform.
They also installed a dedicated computer in the maintenance area with the tutorials readily available whenever questions came up.
As a result, questions dropped significantly, and system usage increased.
The approach worked because training didn’t stop after launch. Employees could revisit information whenever they needed a refresher.
Johnson also recommends keeping training practical and manageable:
Limit sessions to 45 minutes or less
Focus on features employees will use immediately
Use real facility and asset data during training
Provide simple job aids or cheat sheets
Schedule follow-up training sessions after implementation
This last point is especially important.
Employees rarely remember everything from a single training session, particularly when they’re balancing maintenance responsibilities at the same time.
Think of software training the same way you think about preventive maintenance. A single intervention isn’t enough to ensure long-term performance.
Regular reinforcement keeps the system, as well as the people using it, operating effectively.
Of course, training becomes much easier when the software itself is easy to learn. But that’s not always the case.
Overly Complex Tools
When evaluating maintenance software, it’s easy to assume that the platform with the most features will deliver the best results.
The opposite is often true. Many organizations select software packed with advanced capabilities they rarely use.
While these systems may look impressive during a demo, they often come with steeper learning curves, longer implementation timelines, and lower user adoption.
This challenge isn’t unique to maintenance software.
According to Capterra’s 2024 Tech Trends Survey, 58% of software buyers regret at least one software purchase made within the previous 12 to 18 months.
The research also found that buyers frequently limit their evaluation to an initial list of vendors, increasing the likelihood of selecting a solution that isn’t the best fit for their needs.
Complex software can continue creating problems long after implementation.
This is what often happens when you choose software based on the number of features it offers.
So instead, choose software that matches your organization’s size, maintenance processes, and technical maturity.
Most importantly, choose a tool that will make common maintenance tasks easier.
For example, maintenance teams need quick access to complete asset records.
WorkTrek, our own CMMS, allows users to view asset information and maintenance history from a single location.
You also need an easy way to submit and track maintenance requests. WorkTrek includes a centralized work request system that helps ensure nothing falls through the cracks.
You need a straightforward process for creating, assigning, and managing work orders. WorkTrek provides dedicated work order management tools that keep everyone aligned.
Moreover, you need preventive maintenance schedules that adapt to real operating conditions.
WorkTrek allows maintenance tasks to be triggered based on time intervals, usage, meter readings, and other asset-specific criteria.
At the end of the day, successful maintenance software isn’t the software with the longest feature list. It’s the software your team can learn quickly, use consistently, and rely on every day.
Choose one like that, and you can avoid all of these challenges.
Conclusion
Most maintenance software implementation challenges have little to do with the software itself.
More often, they stem from unclear goals, poor communication, or insufficient training.
Address those issues early, and you’ll be far more likely to achieve what every implementation is meant to deliver: better maintenance outcomes with less effort.
Best CMMS Software with Repair Tracking Capabilities
Picking repair tracking software is harder than it seems.
Most tools on the market offer the same list of features on paper, but the differences show up in the details.
That can include how scheduling is triggered, how much of the repair cycle the system actually covers, and what it costs to get the features that matter most.
This article is for maintenance managers and facility teams who want a clear, side-by-side look at the options available.
WorkTrek
To start off our list, we have WorkTrek, our own CMMS solution with repair tracking capabilities.
WorkTrek is designed to cover repair tracking from start to finish, from the moment a request comes in, all the way through task execution, cost logging, and analytics.
In practice, this means your team handles the entire repair cycle in a single system, without needing to switch between tools or manually reconcile data at the end.
Key features:
Work order management
Asset management
Parts & inventory tracking
Preventive maintenance
Checklists & inspections
Invoicing
Reports & dashboards
Even if your team handles repair work across multiple locations, WorkTrek’s asset list keeps everything organized.
Each asset has its own profile with details such as location, category, current status, and full maintenance history, so technicians have the context they need before starting a job.
The hierarchy can span from a location or facility all the way down to a specific piece of equipment, as shown below.
This makes WorkTrek a particularly practical option for facility managers and service teams working with external contractors, where accurate billing without extra admin work matters.
That being said, WorkTrek works well for maintenance and facility teams of all sizes, and it tends to work best for teams that need straightforward end-to-end repair tracking.
As for pricing, there are three paid tiers starting at $29 per user per month.
The features available scale with the tier, with the Enterprise plan adding custom fields, custom workflows, and API access, which are generally better suited to larger organizations with more specific operational requirements.
You can also try the platform for free before committing to a plan.
If you’re looking for a system that handles the full repair cycle without requiring additional tools, WorkTrek is a strong starting point.
Zoidii
Zoidii positions itself as an easy-to-use CMMS built for teams transitioning from pen-and-paper or spreadsheets.
As such, it offers a relatively simple set of features for repair tracking, with an interface designed to be picked up quickly by teams with little prior CMMS experience.
Key features:
Work order management
Preventive maintenance
Parts and inventory management
Purchasing
Checklists
Nested PMs
Beyond the core work order and preventive maintenance (PM) features, Zoidii lets teams track and manage purchase orders directly within the system.
When a repair requires parts that are out of stock, technicians or managers can raise a purchase order, track its status, and connect it back to the repair record, as shown below.
For repair tracking teams, this is useful as it keeps parts procurement tied to the actual work, rather than managing it in a separate spreadsheet or email thread.
It reduces the risk of repairs stalling because nobody knows whether parts have been ordered or not.
Also, while Zoidii does offer features like nested PM, scheduling is still limited to time-based triggers.
Compared to platforms like WorkTrek, which support PM scheduling based on meter readings such as operating hours or pressure, and can automatically generate work orders, Zoidii’s PM capabilities are less responsive to actual asset conditions.
Additionally, nested PMs are only available at Zoidii’s highest paid tier, priced at $75 per user per month.
On the Basic plan at $39 per user per month, you only get standard time-triggered preventive maintenance.
Overall, if you are just stepping away from paper notes or spreadsheets and want to explore a simple solution, Zoidii is worth trying alongside the other systems on this list.
MPulse Software
Next on our list is MPulse Software, an older CMMS that has been on the market for 30 years.
It offers a range of standard repair tracking features along with more advanced capabilities similar to some of the more capable modern solutions on our list.
That said, its interface is noticeably less intuitive compared to most other options in this article, which can slow down adoption for less technical teams.
Compared to the other solutions here, MPulse has more structured qualification tracking for your workers.
Within each employee record, you can define qualifications, set skill levels, log training dates, and track certification expiration dates, as shown in the example below.
Work orders can then be assigned only to workers who hold the right qualifications for the job, reducing the risk of unqualified personnel handling specialized repairs.
Combined with the system’s role-based access controls, this makes MPulse a well-suited option for compliance-conscious repair teams with complex workforce needs, such as those in regulated industries where technician certifications are tied to specific asset types.
Pricing covers three tiers, which sit on the higher end compared to most of the other tools on this list.
It’s worth mentioning that condition-based maintenance and qualification tracking are only available at the higher tiers, with the Enterprise tier requiring a custom pricing quote.
MPulse is a reasonable choice for mid-to-large organizations that need structured workforce management built into their repair tracking system, though smaller teams may find the cost and the interface harder to justify.
Eptura (Ex-Hippo)
Fourth on our list is Eptura, formerly known as Hippo CMMS, a maintenance management platform that has expanded significantly in scope since its rebranding.
At its core, it is a CMMS for work order management, asset tracking, and preventive maintenance, but its standout capabilities are around location-based and 3D asset management.
Through its BIM (Building Information Modeling) viewer, teams can place assets within an interactive 3D model of a facility, link repair history and inspection checklists directly to those locations, and manage work in the context of where it physically happens.
Key features:
Work order management
Asset management with BIM viewer
Inventory tracking
Inspection Checklists
Vendor management & invoicing
Repair history tracking
It is also worth noting that Eptura is not a single standalone product but a platform that brings together multiple specialized solutions, covering asset management, workplace management, and field execution.
As such, it can serve as an integrated system for teams that need to connect maintenance and repair activities, facilities context, and frontline work across sites.
This breadth can be either a strength or a challenge, especially for smaller or mid-sized teams.
Also, while its feature depth is comparable to something like MPulse Software, Eptura is more tailored toward organizations managing complex, multi-building environments where spatial context for assets matters during repair planning.
In terms of pricing, if we look at just the Eptura Assets solution, there are two tiers: Advanced and Power, with multi-location tracking, downtime cost reporting, and task automation available only at the higher Power tier.
The standard maintenance management features are all there, such as work orders, asset tracking, and preventive maintenance, but several of them are extended with AI-driven capabilities layered on top.
Key features:
Work order management
Preventive maintenance
Synapse AI (AI-powered scheduling and intelligent work order routing)
AI predictive maintenance
AI Vision for visual equipment inspections
AI document workflow
As an example of how Oxmaint’s AI features work, the AI Document Workflow allows teams to upload any maintenance document, such as a service manual, inspection report, or equipment log.
The system then extracts and categorizes the content, analyzes it for patterns, forecasts potential failures, and surfaces recommended actions, as shown in the six-step flow below.
For teams working at scale, this can help identify repair tasks that might otherwise be missed in large volumes of documentation, allowing issues to be addressed before they become breakdowns.
Along similar lines, the AI Vision feature lets technicians point their phone camera at a piece of equipment, and the system visually inspects it for signs of wear or potential failure.
We cannot speak to how effective these AI features perform across all equipment types, but they could serve as a useful additional check, particularly for less experienced technicians.
When it comes to pricing, there is one free tier and three paid options.
The AI capabilities are only unlocked from the Agentic tier at $49 per user per month.
This means the Pro plan at $19 per user per month gives you a functional CMMS without any of the AI features, so the AI is effectively a separate upgrade decision, not just a bonus included at a mid-tier price.
If AI-assisted repair detection and scheduling are important to your operation, Oxmaint is the only tool on this list where that is a core part of the product.
Click Maint
Finally, we have Click Maint, a CMMS built for simplicity, not unlike Zoidii.
While Zoidii is aimed primarily at manufacturing and facilities teams, Click Maint covers a broader range of industries and offers a similarly clean, low-friction experience that most team members can pick up without much training.
Key features:
Facility management
Team collaboration capabilities
Inventory & parts tracking
Vendor management
Inspection checklists
Reports & KPIs
You can expect all the standard repair tracking functionality from Click Maint, though it’s less specialized for equipment where maintenance needs to respond to actual usage or asset conditions.
For example, the preventive maintenance feature lets you schedule work and track progress alongside parts used, labor hours, and other costs, as shown below.
However, scheduling is limited to time-based intervals only. So teams managing equipment with maintenance triggers from meter readings or failed inspections would need to look at options like MPulse Software or WorkTrek.
Some of the key industries Click Maint serves include hospitals and clinics, educational facilities, hotels and resorts, and food and beverage processing.
For those environments, the feature depth is well-suited to the work, since maintenance tends to be facility-based and time-scheduled rather than condition-driven.
Combined with features like task checklists for standard operating procedures and work order history tracking, it gives these teams enough structure to stay organized.
Pricing is straightforward: one plan with all features included, at $42 per user per month.
Click Maint also offers a 30-day free trial, which is worth taking advantage of before committing.
If you run a facility where quick adoption and simplicity matter more than advanced maintenance, Click Maint is a practical option to consider.
Conclusion
That covers the six repair tracking software solutions on our list.
Each system covered here takes a different angle, whether that is feature depth, ease of use, AI capabilities, or how well it fits a particular type of operation.
The goal was to give you enough to make an informed shortlist.
From here, the best next step is to explore some trials or demos.
Pick the one or two systems that best match your team’s size, workflow, and budget, and get started.
Repair Tracking Software: A Complete Overview
Key Takeaways:
Facility managers rank work order tracking as their single biggest time-consuming task.
CMMS is the most widely adopted type of repair tracking software.
Repair tracking tools work best when workflows are mapped out before implementation.
Keeping track of repairs gets complicated quickly, especially when teams rely on spreadsheets or lack dedicated systems.
And that’s probably why you’re here.
If you’re a maintenance or facilities manager looking for a clearer picture of how repair-tracking software works and whether it’s worth adopting, this article is for you.
In this overview, we will cover what these systems do, the main types available, their benefits, and what to watch out for during implementation.
What Repair Tracking Software Does
In essence, repair tracking software helps teams manage the full lifecycle of repair work, starting from when an issue is reported until it is resolved.
It’s used across a wide range of settings, from manufacturing plants to property management, or simply wherever equipment and assets need regular attention.
Most solutions share a common set of core features, some of which are shown below.
At a minimum, these systems track work orders from the initial request through assignment and execution.
The best tools make this process straightforward at every step, with managers able to create and assign work orders from a desktop, while technicians in the field submit requests and update their progress from a mobile device.
While the chemicals company needed a few weeks to set up the new platform, the productivity gains are well worth it, with completed maintenance tasks roughly doubling after implementation.
These results are something that Richard Jeffers, managing director at Two6 Services and asset management veteran, would not find surprising.
Jeffers points out that, unfortunately, underreliance on repair and maintenance tracking systems is a recurring issue, with many teams still running their operations out of Excel.
However, he makes the case that as maintenance becomes more preventive and data-driven, teams without the right tools will fall further behind.
Getting the right repair tracking system in place is a straightforward way to close that gap.
Examples of Repair Tracking Software
To get a better sense of what repair tracking looks like in practice, it helps to examine specific solution types.
We’ll cover three types of systems, going over what they do and some examples of each.
Enterprise Asset Management (EAM) Software
EAM software is designed to manage assets across their entire lifecycle, from acquisition through disposal.
These systems are typically adopted by large organizations because of the scale and complexity of what they’re managing.
A large hospital or utility company, for example, can have thousands of assets spread across multiple sites, and keeping track of all of them without a dedicated system quickly becomes unmanageable.
The features that come with EAM software reflect that scope, as shown in the table below.
Feature
Description
Asset lifecycle management
Tracks assets from acquisition through disposal
Financial tracking
Monitors depreciation, ROI, and total cost of ownership
Work order management
Creates, assigns, and tracks maintenance tasks
Compliance and audit trails
Maintains records for regulatory requirements
Multi-site management
Manages assets across multiple locations
As you can see, EAM software covers a wide range of functions, with the full asset lifecycle at the center of everything.
IBM Maximo is one of the most widely known platforms of this type, used across a range of industries from energy to manufacturing.
Shown in the image below is its operational dashboard, featuring capabilities for creating and tracking work orders, predictive maintenance, and analytics.
Beyond these core features, a tool like Maximo includes AI and IoT-driven predictive maintenance, compliance tracking, and spatial asset management.
While some of these features are shared with other repair tracking tools, the scale and depth of EAM platforms mean they tend to be less focused on the day-to-day simplicity that field technicians or smaller teams need.
They are systems built for enterprises, which means there is a learning curve involved, and implementation typically requires significant time and resources.
For organizations with large, complex asset portfolios, this might be a worthwhile investment, while for others, it may be more than necessary.
Field Service Management (FSM) Software
FSM software is designed with the main focus being the logistics side of repair work, making sure the right technician gets to the right job as efficiently as possible.
The feature set follows that priority, covering things like dispatch, scheduling, route planning, and real-time communication between the office and field staff.
Feature
Description
Dispatch and scheduling
Assigns jobs based on technician location, skills, and availability
Route optimization
Plans efficient travel routes between service calls
Mobile work orders
Technicians access and update jobs from the field
Streamlined communication
Sends real-time arrival estimates and status updates
Parts and inventory
Tracks van stock and field parts usage
Service contract management
Manages SLAs, warranties, and recurring service agreements
These tools are built around the idea that the technician is constantly moving, and the system’s job is to make that movement as smooth as possible.
The platform gives dispatchers a real-time view of technician availability and job status, making it straightforward to assign and adjust work as the day unfolds.
It is a strong fit for organizations like telecom providers or home services companies, where dispatching field teams is a core daily operation.
For teams working primarily within a single facility, though, FSM may not be the best choice, as the internal repair tracking and asset history features tend to be lighter.
In that case, a more maintenance-focused system would likely be a better fit.
Computerized Maintenance Management System (CMMS)
CMMS tools are some of the most widely used types of maintenance systems, with data like the following RS report showing wide adoption over alternatives like EAM tools.
The decrease in EAM software usage in favor of CMMS makes sense.
After all, EAM covers a broader range of financial and enterprise functions, but that added scope can make it more complex than necessary.
So, for most teams, a CMMS is the most practical fit for repair tracking because it is built for day-to-day operations.
The core features of these systems are outlined below.
Feature
Description
Work order management with mobile field access
Creates, assigns, and tracks maintenance tasks from request through completion
Preventive maintenance scheduling
Automates recurring maintenance based on time intervals, meter readings, or usage thresholds
Asset management
Maintains a centralized registry of equipment with service history, warranties, and location data
Inventory and parts tracking
Monitors spare parts stock levels, usage per work order, and triggers reorders when stock is low
Reporting and analytics
Tracks KPIs such as mean time between failures, maintenance costs, and technician productivity
WorkTrek is a good example of a CMMS built with repair and maintenance teams of all sizes in mind.
It covers the core work order tracking functions without adding unnecessary complexity, which means teams can get it up and running without a steep learning curve.
On top of that, WorkTrek includes a mobile app that gives technicians full access to their work orders and tasks while in the field.
From the field, workers can submit repair requests and update job status directly from their phone, acting as an FSM tracker.
Plus, all activity is centralized in one place, giving managers a clear overview of ongoing repairs and scheduled maintenance at any given time.
That combination of accessibility and focused functionality is exactly what makes CMMS the go-to choice for repair tracking.
Biggest Mistakes Companies Make During Implementation
Finding the right type of repair tracking software is only part of the work.
How you implement it and how prepared your team is largely determine whether it delivers the results you’re looking for.
Here, we’ll cover three common mistakes during implementation.
Implementing Before Defining Processes
Many companies buy repair tracking software before they have a clear picture of how their repair process should actually flow.
Getting a capable system in place is one thing, but expecting it to structure the entire process for you is another.
In fact, Kurt Johnson, former product manager for Fluke’s eMaint CMMS, points out that most CMMS implementations fall short because of preparation and change management, regardless of how good the software is.
While we simplified the steps, each part of the workflow should be carefully looked at to see where the repair tracking tools come in and the procedures that need to be followed.
When logging repair work, for instance, you might define which data points are required, such as parts used or time taken, and then configure the system to enforce that through mandatory fields or preset templates.
Going through each step of your workflow in this way gives you and your team the needed clarity to use the tool correctly.
Choosing Software That’s Too Complex
Repair tracking systems vary widely in scope, and a common mistake is selecting a platform that goes well beyond what your team actually needs.
When a system has more features than the team can realistically use, parts of it get ignored, and the tool ends up being used at a fraction of its capacity.
If you’re managing assets across a large enterprise with dedicated IT resources, that setup may well be justified.
But for most, it’s a significant amount of overhead for a system that covers far more than their repair tracking needs.
A better approach is to map out your repair-tracking flow first, and use free trials or demos to test how well a tool supports your workflow before you commit.
That way, the decision is based on actual fit rather than feature count.
Underestimating Change Management
All the planning and preparation can go to waste if your team isn’t on board with the new system.
Even well-chosen software tends to fall short when employees aren’t meaningfully involved in the rollout.
There are three aspects of change management worth paying attention to here.
Beyond training, you also want to involve workers before the system goes live.
They should have input on how workflows are structured and explore which features should and can be a part of their day-to-day routine.
Considering that frontline technicians understand the actual work better than anyone else, their perspective can often surface practical issues that wouldn’t be visible from a management level.
That can be the case even after the system is live, so keeping feedback channels open is essential.
Ultimately, only by listening to your team and acting on what they share can you make a repair tracking system rollout that holds up over time.
Conclusion
That covers everything you need to know about repair tracking software.
You have a solid understanding of how this software functions, what to look for in your own solution, and common challenges encountered during implementation.
Hopefully, we provided enough information to help you make a more informed decision about your operations.
Whether you’re comparing software options or planning a rollout, use what you’ve read here to move forward with confidence.