









What is Mean Time To Recovery?
Mean Time To Recovery (MTTR) is a critical reliability engineering and IT operations metric. It measures the average time required to restore a system, service, or component to full functionality after a failure or incident occurs.
This recovery period spans from detecting an issue until normal operation resumes.
To understand MTTR thoroughly, let’s break it down into its key components:
The “clock” for MTTR starts running as soon as an incident is detected, whether through automated monitoring systems or user reports.
It encompasses several phases of the recovery process: the time needed to detect and report the issue, diagnose the root cause, implement a fix or workaround, and verify that the system has returned to normal operation.
For example, if a web service goes down, MTTR would include the time to notice the outage, identify the cause (perhaps a database connection issue), restart necessary services, and confirm that the website is functioning correctly.
MTTR can be calculated by summing up the total downtime from all incidents over a given period and dividing by the number of incidents.
For instance, if a system experienced three outages in a month with recovery times of 30 minutes, 45 minutes, and 15 minutes, the MTTR would be (30 + 45 + 15) ÷ 3 = 30 minutes.
Organizations often use MTTR alongside other reliability metrics, such as Mean Time Between Failures (MTBF) and Mean Time To Failure (MTTF), to assess their operational resilience. A lower MTTR indicates better incident response capabilities and more robust recovery processes.
Modern DevOps practices aim to minimize MTTR through strategies like automated rollbacks, redundant systems, and well-documented incident response procedures.
In practical terms, MTTR is a key performance indicator for IT teams and can influence service level agreements (SLAs).
For instance, a company might commit to an MTTR of under 4 hours for critical systems and strive to resolve major incidents within that timeframe.
MTTR Calculator
MTTR Calculator
What is the difference between Mean Time to Repair, Mean Time to Restore, and Mean Time to Recover?
While they may sound similar, each measures a distinct aspect of how organizations handle system issues.
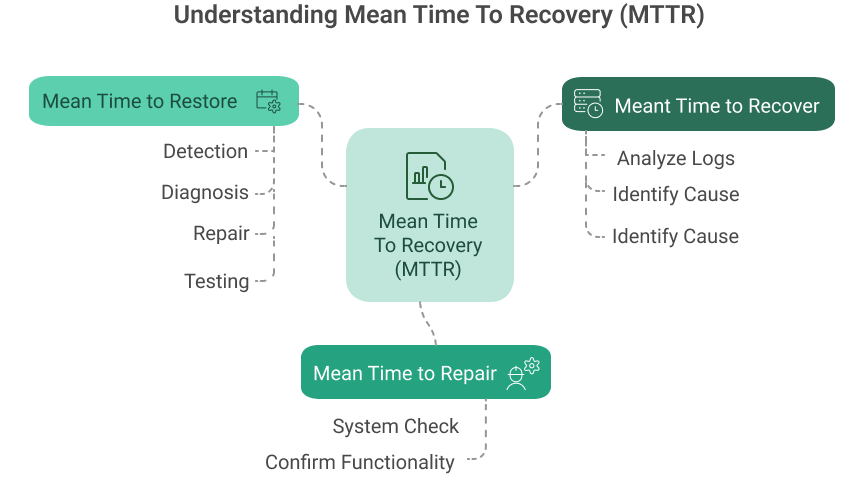
Mean Time to Repair (MTTR) specifically focuses on hands-on fixing time—when technicians or engineers actively work to repair a failed component or system. Think of this as the actual time a mechanic spends replacing a faulty part in your car.
It starts when the repair work begins and ends when it is complete. For example, if a server’s hard drive fails, MTTR would measure only the time spent physically removing and replacing the drive.
Mean Time to Restore (MTTR) captures a broader window – the total time from when a system fails until it returns to service, including activities beyond the repair work. This encompasses detection, diagnosis, repair, and testing times.
Using our car analogy, this would include noticing the problem, taking it to the shop, waiting for parts to arrive, having repairs done, and completing a test drive to ensure everything works. The server example would include diagnosing the issue, obtaining a replacement drive, installing it, restoring backup data, and verifying system operation.
Mean Time to Recover (MTTR) is the most comprehensive measure, encompassing the entire incident lifecycle from failure to full operational recovery. Beyond repair and restoration, it includes any additional time needed for the system to return to its normal operational state and performance levels.
This might involve data synchronization, cache warming, or queue processing. Imagine if, after fixing your car, you needed to let the engine run for an hour to recalibrate various sensors – that extra time would be part of recovery but not repair or restoration.
In our server scenario, this would include time for the system to rebuild its cache, process any backlog of requests, and return to normal performance levels.
What does it all mean?
Repair time sits at the center, focused on fixing what’s broken. Restoration time encompasses repair but adds the surrounding activities needed to get the system running again. Recovery time includes everything in restoration plus the additional time required to return to normal operational status.

Here’s a practical example to illustrate the differences: Consider a critical database failure:
Recovery time: 3.5 hours, including the additional time needed for the system to process the backlog of transactions and rebuild its cache
Repair time: 30 minutes to replace the failed database server
Restore time: 2 hours, including diagnosis, repair, and data restoration from backups
Get a Free WorkTrek Demo
Let's show you how WorkTrek can help you optimize your maintenance operation.
Try for free