









What is Mean Time to Resolve (MTTR)
Mean Time to Resolve (MTTR) is a critical maintenance service management and operations metric. It measures the average time required to fully resolve an incident or problem from when it is first reported until it is completely fixed.
This includes the time spent actively working on the issue and any delays due to escalations, waiting periods, or administrative overhead.
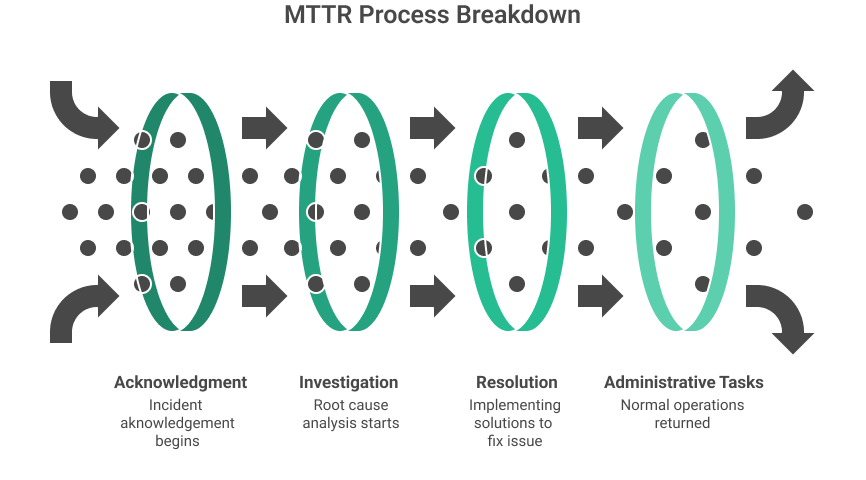
Examples of MTTR
To understand MTTR more deeply, consider a simple example: If one incident takes 2 hours to resolve and another takes 4 hours, the MTTR would be 3 hours.
However, the real value of MTTR lies not in individual calculations but in tracking it over time to improve service quality and operational efficiency.
The resolution time starts when an incident is first reported through any channel (such as a help desk ticket, monitoring alert, or customer complaint) and continues until the underlying cause is addressed and normal service is restored.
This differs from metrics like Mean Time to Acknowledge (MTTA) or Mean Time to Repair (MTTRepair), which measure different portions of the incident lifecycle.
Importance of MTTR
MTTR is particularly important because it directly impacts business operations and customer satisfaction. A high MTTR might indicate several underlying issues: insufficient resources, complex technical problems, poor troubleshooting procedures, or team communication breakdowns.
By tracking and working to reduce MTTR, organizations can improve their incident response capabilities and overall service reliability.
For example, suppose a company’s MTTR for critical database issues is 4 hours.
This means that on average, when a database problem occurs, customers and internal users might experience disruptions for 4 hours.
By analyzing patterns in resolution times and implementing improvements like better monitoring tools or standardized troubleshooting procedures, the organization might reduce this to 2 hours, significantly minimizing business impact.
Calculate MTTR
Let’s start with how MTTR is calculated. Imagine you’re tracking incidents over a month. For each incident, you measure the time from when it was reported until it was fully resolved. Let’s work through a practical example:
Incident 1: Database outage
- Reported: Monday 9:00 AM
- Resolved: Monday 2:00 PM
- Resolution time: 5 hours
Incident 2: Network connectivity issue
- Reported: Wednesday 3:00 PM
- Resolved: Thursday 10:00 AM
- Resolution time: 19 hours
Incident 3: Application error
- Reported: Friday 11:00 AM
- Resolved: Friday 3:00 PM
- Resolution time: 4 hours
To calculate MTTR, sum all resolution times and divide by the number of incidents: (5 + 19 + 4) ÷ 3 = 9.33 hours MTTR
Now, let’s explore strategies for improving MTTR. Think of MTTR reduction like optimizing a race car pit stop – every second counts and improvement comes from refining each step of the process.
- Enhanced Detection and Diagnosis: Think about how doctors diagnose illness. Just as they use various tests and instruments, you want robust monitoring systems that can:
- Automatically detect issues before users report them
- Provide detailed error logs and system states
- Use AI/ML to suggest potential root causes based on historical data
- Streamlined Response Processes: Consider a fire department’s response system. Like how they have clear protocols for different types of fires, you should:
- Develop standardized response procedures for common issues
- Create detailed troubleshooting flowcharts
- Maintain updated documentation accessible to all team members
- Implement automated remediation for known issues
- Knowledge Management Improvement: Think of this as building a library of solutions:
- Document all resolution steps for each new type of incident
- Create searchable knowledge bases
- Record video tutorials for complex procedures
- Regular team knowledge-sharing sessions
- Team Organization and Communication: Like a well-oiled emergency response team:
- Establish clear escalation paths
- Define role-based responsibilities
- Use integrated communication tools
- Conduct regular cross-training sessions
- Root Cause Analysis and Prevention: This is similar to preventive medicine:
- Analyze patterns in incidents
- Identify and address systemic issues
- Implement preventive measures
- Regular system health checks
To measure improvement, track these additional metrics alongside MTTR:
- Time to detect incidents
- Time spent waiting for resources
- Time spent on actual resolution work
- Time spent on verification and closure
MTTR Calculator
Below is a simple calculator to calculate mean time to resolve.
Mean Time to Resolve (MTTR) Calculator
Understanding MTTR Components
Mean Time to Resolve measures the average time taken to fully resolve incidents from detection to completion. This calculator breaks down the resolution process into key phases to help you identify areas for improvement:
- Detection Time: Time from incident occurrence to discovery
- Response Time: Time from discovery to starting work
- Diagnosis Time: Time spent identifying the root cause
- Resolution Time: Time spent implementing and verifying the fix
Your Mean Time to Resolve analysis will appear here.
How can Maintenance Organizations improve MTTR?
MTTR improvement is similar to optimizing a hospital’s emergency response system—it requires coordinated improvements across people, processes, and technology.
First, let’s understand the key components that affect MTTR in maintenance organizations. The resolution time includes detection, diagnosis, repair planning, parts acquisition, actual repair work, testing, and documentation. Each of these stages presents opportunities for improvement.
Maintenance organizations should invest in comprehensive training programs, starting with the people aspect. Just as medical residents undergo structured training with increasing responsibility, maintenance technicians should have clear skill development paths.
This includes cross-training across different equipment types and systems, which helps create a more flexible workforce that can respond to various issues. Regular certification programs ensure technicians stay current with new technologies and maintenance techniques.
Consider implementing a robust Computerized Maintenance Management System (CMMS) for process improvements. This works like an advanced medical records system, tracking equipment history, maintenance procedures, and repair outcomes.
The CMMS should include detailed equipment information, maintenance schedules, spare parts inventory, and standard operating procedures.
When a critical pump fails, technicians can quickly access its maintenance history, common failure modes, and step-by-step repair procedures.
Technology plays a crucial role in modern maintenance operations. Consider implementing condition monitoring systems similar to patient monitoring in hospitals. These systems use sensors to continuously monitor equipment health, detecting potential issues before they cause failures.
For instance, vibration sensors on rotating equipment can detect bearing wear before catastrophic failure occurs, allowing for planned maintenance rather than emergency repairs.
Spare parts management significantly impacts MTTR. Think of it like a hospital’s blood bank – you need the right inventory available when needed, but storing too much is costly. Implement a strategic spare parts program that:
- Analyzes historical failure data to identify critical spares
- Uses predictive analytics to optimize inventory levels
- Establishes relationships with reliable suppliers for quick delivery
- Implements tracking systems to locate parts quickly within the facility
Communication and documentation systems are vital for MTTR improvement. Create standardized procedures for incident reporting, similar to medical triage protocols. This should include:
- Clear criteria for problem severity classification
- Defined escalation paths for different types of failures
- Standard troubleshooting guides for common issues
- Documentation requirements for all repairs
Root cause analysis (RCA) should become a standard practice, much like post-operative reviews in medicine. After significant failures, conduct thorough investigations to:
- Identify the underlying causes of the failure
- Document lessons learned
- Update maintenance procedures based on findings
- Share insights across the organization
Performance metrics tracking is essential for continuous improvement. Beyond just MTTR, track related metrics such as:
- Mean Time Between Failures (MTBF)
- First-time fix rate
- Spare parts availability
- Technician response time
- Planned vs. unplanned maintenance ratio
Get a Free WorkTrek Demo
Let's show you how WorkTrek can help you optimize your maintenance operation.
Try for free